第 4 天 深度神经网络¶
经过前 3 天,我感觉「悟」了。我好像已经明白大模型在干嘛了,好像也没那么神奇。它无非就是一堆被不断尝试出来的「最佳参数」在做加减乘除嘛。
听说神仙的世界天上一天,我们这地下一年。我们这 3 天中的每一天,在机器学习的发展史上都切实历经了 10 年左右的摸索。直摸到第 3 天的午夜,神经网络仍还是机器学习领域里的吊车尾。甚至它自己的顶级会议 NIPS 都大量拒收神经网络相关的论文,转向了当时更为主流的统计机器学习方法。彼时的神经网络和当下炙热的「大模型」是无法同日而语的。
所以说,手搓「多层感知机」的我们距离理解「大模型」虽已不远,亦得耐下性子再行一段。
我看到不少的材料和书籍把 前 3 天的内容归纳进「入门阶段」或者「知识准备」的单元。我感觉这并非偶然,从这往后,神经网络确实迎来了巨变。
上世纪 90 年代遭受冷遇的,和现如今热到发烫的神经网络,究竟经历了什么改变?
4.1 神经网络的巨变¶
4.1.1 计算平台的转变¶
我们知道现在 GPU / TPU / NPU 这些并行计算平台已经成为神经网络的主要计算平台。我想,那是因为 CPU 主频的提升早已达到瓶颈,人们才转而追求并行。而曾经 CPU 才是绝对的主流,每一代新 CPU 的发布,人们都热烈讨论这主频又提升了多少,给程序员们带来了多少无痛的性能提升。一直到昨天我们使用的现代 CPU,拥有数 GHz 的 CPU 还训练了十来分钟。想 1990 年的 Yann LeCun ,他是用一颗 16 MHz 的 CPU 来训练的他的神经网络。想想看,每一次的不收敛该多么让人心烦……
平心而论,神经网络在当时对算力的追求确实超越了时代。站在现在回头看,就有点像一本穿越小说 —— 给我一个合成装甲旅我能回到古代打遍全球吗?—— 其实问题并不在于能不能打遍,而在于古代有没有合成装甲旅。以及就算你有了,你怎么搞定它的运输补给和指挥通信之类的配套?
当然,我是有我的合成装甲旅的,且齐装满员。现在就是我放下 CPU,购入一颗 GPU,给我亲爱的 PyTorch 一个全新肉身的恰当时刻了。
4.1.2 创新方法的分层¶
神经网络初期,一篇论文提出的新方法,往往是直接解决实际问题。但逐渐的,新方法变得不再是直接解决实际问题,而是解决"实际问题带来的技术问题中的技术瓶颈"。
比如图像识别问题,早期的方法可能直接针对"如何识别图像"这个问题。但后来的创新可能针对"如何让模型训练得更快"、“如何减少显存占用”、"如何提高数值稳定性"这些更远离产品的、技术性的问题。这就意味着后续的部分概念会变得越来越难以通过想象与事实连接,我们理解它们的难度在加大。而面向用户提供产品的我们的模样会逐渐从按图索骥的、单人完成作品的小木匠逐渐变成产业链里的集成商,交付的产品中手作的含量会越来越低,理解和集成的含量会越来越高。
4.1.3 可解释性的骤降¶
前 3 天我们构建的网络,每一步都可推导、可计算,每一步都有其明确的数学意义。我可以清晰理解模型在做什么、为什么这样做。但继续往前走,我感觉神经网络的需要进化逐渐变成 —— 这样做好像「make sense」,然后试试,果然可以,就马上变成最佳实践。关于这些实践的原理性解释往往后置数年甚至根本没有,尤其在资本加持下,整个产业竭力透支预期的今天更是这样。
今日 OpenAI 的市销率值已经超越了 2000 年互联网泡沫的峰值,市盈率更是高到整型翻转了都。这强烈的 PS、PE 值肯定是体现了全世界人民对神经网络的热忱期待及其应用前景的无限憧憬。但另一方面,肯定也意味着资本对产业的强力催熟和对学术可解释性的选择性放弃。对资本来说这是不是好事我不知道,但是对我们这些初涉大模型领域的学习者来说,却肯定是一个坏消息。因为今天觉得对的实践,隔天可能就会变成错的。我个人感觉到,认可一个东西是相对容易的,就算是错的怎么也能圆成对的。但是已经「学会了」「认可了」了的观念,再想打翻来由对转错却相当困难。否认自己比认可自己难太多。从这一天开始,我觉得挺有必要对所涉概念抱有更审慎的态度,面对每个概念需要留意区分「That is it」和「That makes sense」的分野。
4.1.4 这一切的开始 —— 神经网络走向「深度」¶
上面这些对算力的渴求、可解释性的畸低肯定都是 90 年代神经网络遇冷的原因之一。但我觉得最核心的原因,还是在输出上 —— 无论你挑费再高,只要产出够靓,人们还是会爱你。可当时的神经网络有一个致命的问题 —— 它无法走向「深度」。
何谓「深度」?
1969 年,Marvin Minsky 出版《感知机》,从数学上证明了单层网络的表达力上限。所以,神经网络从单层走向了多层。昨天,我们构建了一个 4 层的神经网络,解决了单层神经网络难以解决的非线性问题。
很容易想象,我们继续增加层数,神经网络应该就能持续提升它的表达力,拟合越来越复杂的函数,帮助我们解决越来越困难的问题。
很容易证明,继续增加神经网络的层数,我们应该获得一个效果「不劣于」增加层数之前的旧网络的新网络 —— 最次的结果,我们只要写 y=x,让新的层保持无效就好了嘛。但事实却让人大跌眼镜。
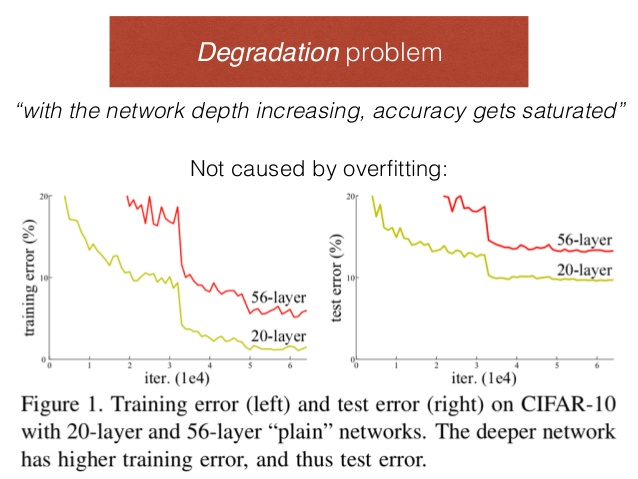
图 4-1 在 CIFAR-10 数据集上,更多层数的网络反而准确率更低
2015年,还在北京中关村微软亚洲研究院任职的何恺明(1984 年 -)发表了 ResNet 的论文《Deep Residual Learning for Image Recognition》。这篇论文开篇的第一个图就是图 4-1,他指出一个现象 —— 越深层的网络,反而会得到更糟糕的表达。
这个相当反直觉的现象,同一时期其实已经被不少人注意到了,并且其中一些人已经在着手解决这个问题了。
4.2 解开「深度」封印的仙人们¶
4.2.1 AlexNet 的 DropOut¶
深度神经网络首先带来的问题就是「过拟合」。深度神经网络显著提升了网络的表达力,它使得网络就像一个记忆力突然暴涨的孩子。不知道大家有没有遇见过这样的孩子,你发现聪明的他突然不会举一反三了。因为他发现相比起理解老师教的知识,他直接把整本课本背下来更省力。虽然很怪,但我确实见过这样的孩子。类似这样的表现在神经网络中被称为「过拟合」 —— 精确背诵了课本,而没有去拟合背后的规律,结果是课后习题都不会做。
AlexNet 为深度神经网络带来了它給「过拟合」的解 —— DropOut。
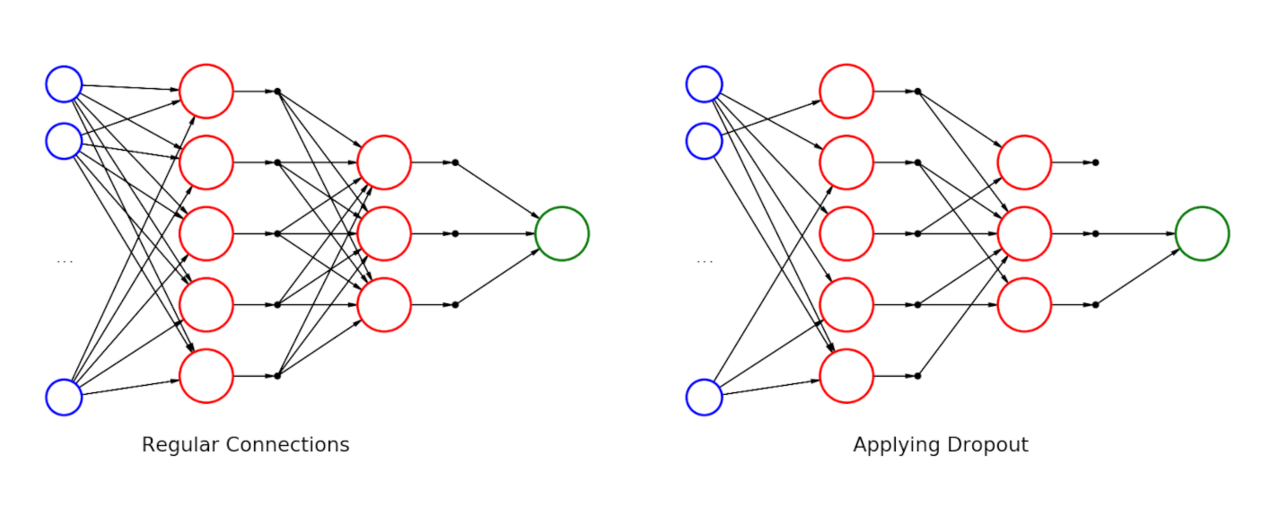
图 4-2 DropOut
AlexNet 的作者似乎不太喜欢用图表说明问题,所以我们找了图 4-2 来说明 DropOut 是如何在工作。
可以看到,右侧应用了 DropOut 的网络和左边相比,就是少了一些连线。我们将第 1 列的蓝色节点分别记为 \(x_1\) 和 $ x_2 $,我们拿第 2 列最上面一个红色节点记为 $ y $ 来说明它在 DropOut 前后的区别。
式 4-1 应用 DropOut 前
式 4-1 是应用 DropOut 前 $ y $ 的计算方法。应用 DropOut 后,$ y $ 的计算方法变成。
式 4-2 应用 DropOut 后
可以看到,应用 DropOut 后 $ y $ 把 \(x_1\) 的值給置零,給 丢弃 了。这样的操作会在每次前向预测时,随机应用在网络中的节点上。
Alex 在论文中说这是一种「低成本的结合不同模型的方法」。他的意思是通过 DropOut,他实际上训练了千万个不同架构的神经网络。最后推理时在这些多个既独立又相关的网络中,通过求均值的方法,达成抵消误差、弱化异常值的效果。
我理解这就像是让那些记忆力超群的孩子闭上课本里的某些页,让他无法强行背诵课本,而被迫去思考这些被断链的公式推导背后的逻辑。—— 目的是实现「反过拟合」,或拽个术语「泛化」。
实际应用时,DropOut 通常应用在神经网络的前几层,对于后方那些越来越「蕴含了习得规律」的层,通常是不丢的。另外,DropOut 仅仅是训练技巧,推理时还是使用所有参数。
4.2.2 VGGNet 的 3x3 小卷积核¶
VGG 是牛津大学视觉几何组 Visual Geometry Group 的缩写,2014 年他们推出的 VGGNet 在 ImageNet 比赛中夺冠。他们认为他们的主要贡献是把之前 7x7 甚至更大的 11x11 的卷积核换成 3x3 的小卷积核,从而达成了让神经网络更深的目的。
新名词! —— 「卷积」
昨天我们面对 28x28 的图片时,直接把它的每一个像素摊平送进了一个 784 个节点的层里。有效。但其实我们想想,这些像素点它们并不是独立存在的 —— 像素是和它附近的像素在一起构成意义的。当然,理论上,我们直接把它们摊平送进神经网络,网络应该也能逐渐习得这一认知。但在走向深度网络的过程中,我们面对的问题并不是更深的网络表达力不足,真正的问题在于我们每个找到好的方法去训练越来越深的网络。
就像一名庸师忽遇天才少年,不是它不行,是我们惊慌失措。所以,我们还是尽量告诉它一些基本的道理,减少它学习的难度。对于图像的学习,我们想告诉它 —— 像素是以矩阵形式存在的,每个像素和它周围的像素组合在一起产生意义。告诉它的方式便是「卷积」。
我们用一个 5x5 的图片举例,我们假设它只有黑白两种颜色,1 代表黑,0 代表白。
式 4-3 原始图像
稍稍想象一下,这是一张左边是黑色,右边是白色的图片。然后我们自定义下面这么一个 2x2 的矩阵。
式 4-4 卷积核
这个矩阵可以叫它「卷积核」,也可以叫它在神经网络爆炸之前的名字「算子」。
接下来,我们用这个式 4-4 卷积核中的每一项跟式 4-3 原始图像左上方的 2x2 的子矩阵的对应项做相乘,然后相加。就像这样。
式 4-5 对应项相乘
然后我们把这 $ 2 \times 2 = 4 $ 项相加。
式 4-6 对应项相乘后相加
得到结果0。我们把这个结果写在一个新矩阵 Z 的左上角,新矩阵 Z 的其他值我们暂时记为 nil。
式 4-7 算了 1 项的新矩阵 Z
然后,我们把这个所谓卷积核往右滑动一步,重复上面的过程。
式 4-8 滑动一步后的对应项相乘
先乘再加得到结果 1。
式 4-9 滑动一步后的对应项相乘后相加
然后我们把结果也记在相应的右侧一步的位置,更新我们的新矩阵 Z。
式 4-10 填好了 2 项的新矩阵 Z
就这样循环往复,我们一直右滑,滑到头了就换行继续滑。最终我们会把新矩阵 Z 給填满。
式 4-11 填满的新矩阵 Z
这个矩阵 Z ,有时会被叫做「特征图」Feature Map。上述这个计算的过程,便是所谓的「卷积」Convolution。
手动做过一遍,再看卷积的公式就亲切多了。
式 4-12 卷积的离散域求和表达
式 4-13 卷积的连续域微积分表达
以上是两种常见的数学表达,不管咋写,其实就是输入图像和卷积核对应相乘然后相加。我们可以从式 4-11 中看到,通过这样的卷积操作,我们实际上做的是 —— 把原始图像的边缘給提取出来了。
但在得到边缘的同时,我们也丢失了其它维度的信息。所以,通常会使用多个卷积核对原始图像进行处理,等于是我们从多个角度去查看这个图像,以尽量保留多维度的信息。
回到 VGGNet,不同于我们选择的 2x2 的卷积核,VGGNet 使用的卷积核是 3x3,相较 VGGNet 之前普遍被使用的 11x11 和 7x7 的卷积核显著减小。
VGG 认为更小的卷积核能加深网络深度的原因有二。一个是他认为 2 个 3x3 的卷积核堆积也能解析出类似 5x5 卷积核的特征图,但是参数量却明显减少。
式 4-13 不同大小卷积核的参数量对比
再一个是如果是 2 个 3×3 卷积核,那么还会额外获得一次在这两层之间插入 ReLU 的机会。而这无疑会增强网络的非线性拟合能力。
通过 VGG 的创新,神经网络从 AlexNet 的 8 层进一步拓深到了 19 层。另外,VGGNet 在设计网络时使用了大量的「单调重复」,它所有的卷积层都是一模一样的结构。虽然他们在论文中提到这是受前人启发,并不掠人之美。但他们这个 VGGNet 远比前人的更加单调纯粹,我相信这对后续 Tranformers 暴力的同构堆叠产生了影响。
4.2.3 GoogLeNet 的 Inception 子网络¶
顾名思义,这个网络来自 Google AI 团队。但它们把字母 L 大写了,想来应该是有意致敬 Yann LeCun 创建的第一个卷积神经网络 LeNet。双关名字,有点意思。
Google AI 团队将这个网络里的基本模块命名为电影《盗梦空间》的名字 Inception,取意电影中的一句台词“we need to go deeper”,可见 Google AI 团队立志于进一步将神经网络推向深度的想法。
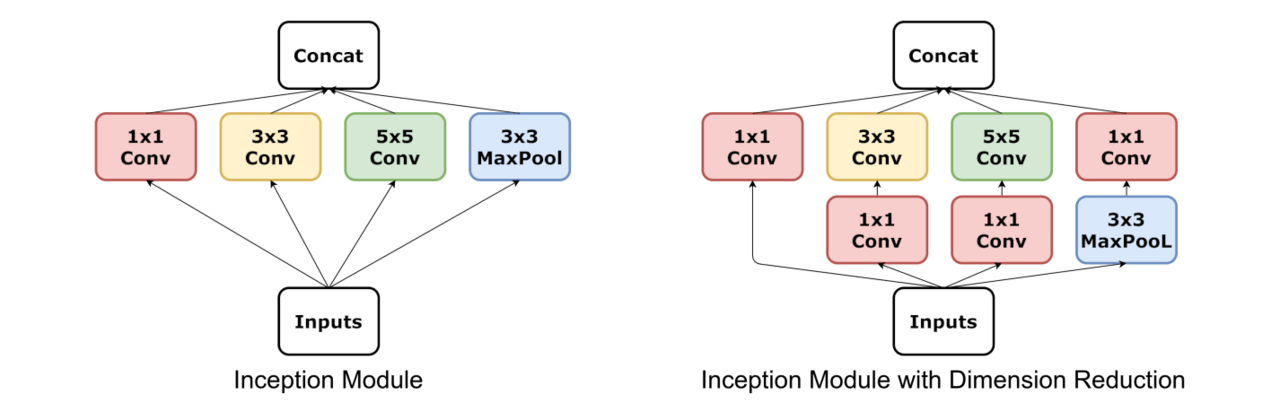
图 4-3 GoogLeNet 中的 Inception 模块
可见图 4-3,这个 Inception 模块在同一层的一次变换中,使用多个不同大小的卷积核对图像进行处理,来捕捉不同维度的特征。Google AI 团队把 Inception 模块作为基本单元嵌入到 GoogLeNet 中。所以,GoogLeNet 等于是把网络給拓宽了,在每一层提升了特征提取的效率,使得神经网络进一步拓深到了 22 层。他是把一个 Inception 模块算作一个层来数的,要按我的数法,它已经来到了 40 多层…… 另外,在图 4-4 中我们可以看到,GoogLeNet 还在网络的半截路上分出两个分支直通最终的 Loss 计算,这也在一定程度上增加了网络的可训练性。
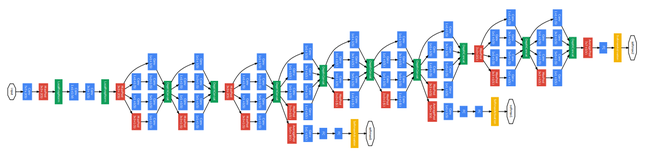
图 4-4 GoogLeNet
另另外,Inception 模块的具体结构是 Google AI 团队通过在 ImageNet 上的大量实验得来的,也就是说从这里开始,我们已经离开了数学精密证明的领域,一脚踏入了「That make sense」的领域。个人的聪明才智逐渐越来越需要嫁接在平台和资本的枝桠上才能闪耀光芒了。
4.2.4 ResNet 的残差连接¶
正如前文所言,ResNet 是一个中国人的发明。它源自一个非常简单的想法 —— “孩子学不进去,你就别逼他学了”。
前面我们已经说过,只要我在更深的网络层都写上 $ y = x $ ,它最次也就等价于那个较浅的网络,万万没道理变得更糟。所以后来人们逐渐意识到这不是孩子的问题,是家长的错。不是深度网络出了问题,而是我们还没学会如何去训练那样深的网络。
用笨拙的方法强行去训练一个深的网络,就像是一名不成熟的家长一意孤行地强摁着一名开智早的孩子傻学,很有可能孩子的考试分数上得不到提高,还有一定几率搞出弃世、厌学等坏结果。而 ResNet 就像是给了孩子一个松解的机会。
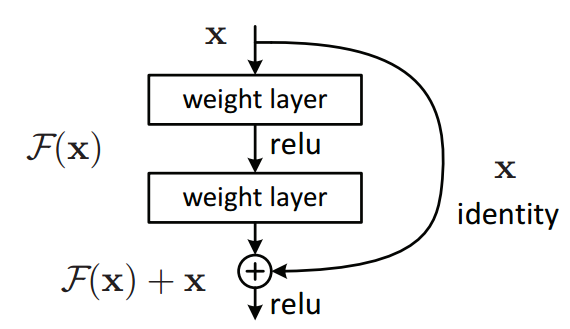
图 4-4 残差学习模块
图 4-4 便是 ResNet 论文中说明它最核心组件「残差学习」的原图。其中两个 weight layer 夹着一个 relu 就是我们之前的多层神经网络,最上面的 $ x $ 是网络的输入,唯一的差别就是那根从右边弯下来的箭头。很多材料里用下面这种表达式表示「残差学习」,我感觉很能帮助理解。
式 4-14 残差学习的表达式
难得见到比图像还简单的数学表达。这式 4-14 中 $ \mathcal{F} $ 表示神经网络的前向推理过程,$ W_i $ 表示网络中的权重。所以,一个普通的多层神经网络的表达是 $ \mathbf{y} = \mathcal{F}(\mathbf{x}, {W_i}) $,即在权重 $ W_i $ 的参与下,把 $ \mathbf{x} $ 变成 $ \mathcal{F}(\mathbf{x}, {W_i}) $ 。残差学习仅仅是在这后面又加了一个 $ \mathbf{x} $ ,这是什么意思呢?
它的意思是,如果在这个阶段你学不到什么东西,网络会得到一个超低成本的休息的机会 —— 只要将 $ \mathcal{F}(\mathbf{x}, {W_i}) $ 置零,网络便会退化成 $ \mathbf{y} = \mathbf{x} $,即将这一层失效化,让它等价于没有这一层的更浅层网络。
事实证明,残差网络非常有效。何恺明凭借残差学习成功训练了一个超过 150 层的神经网络于 2015 年勇夺 ImageNet 竞赛的冠军。并且,在 ResNet 论文中,他表明他用实验证明了残差学习足以支持神经网络的深度拓展至超过 1000 层。
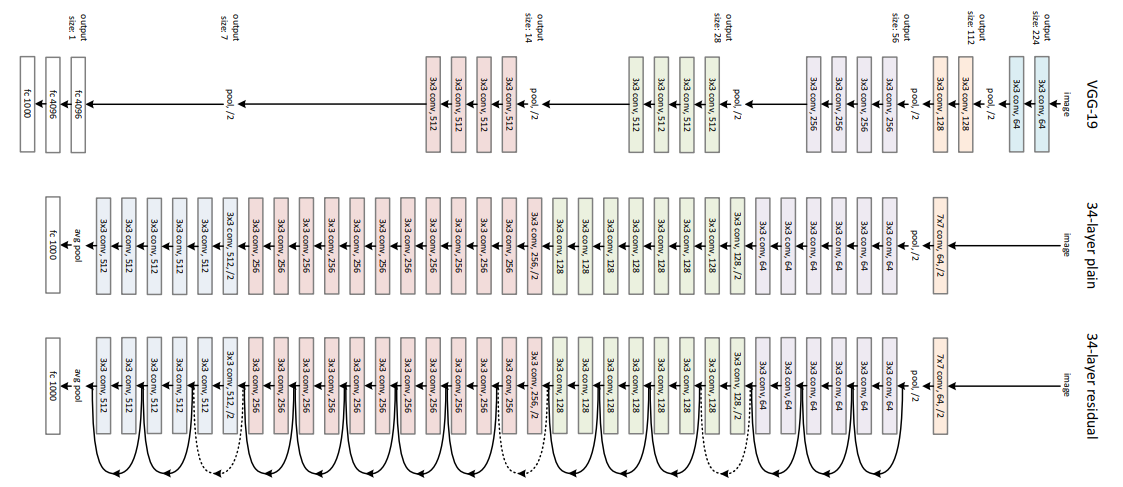
图 4-5 最下面的是 ResNet-34
顺便一提,在微软的 ResNet 夺冠的同年,获得第二名的是 GoogLeNet 的后续版本 Inception-v3。其实在 ResNet 差不多的同时期,还有 Highway Network 的门控技术、 DenseNet 的稠密连接技术(注意:这里的「稠密网络」和经常在新闻上看到的和 MoE 结构相对的「稠密网络」不是一回事)等等许多创新也陆续为神经网络的深度拓展做出了重要贡献。
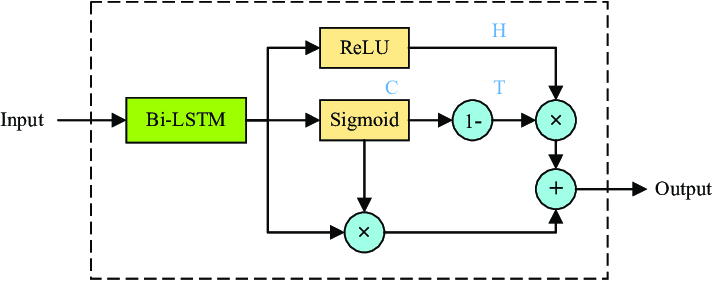
图 4-6 Highway Network 中的关键模块
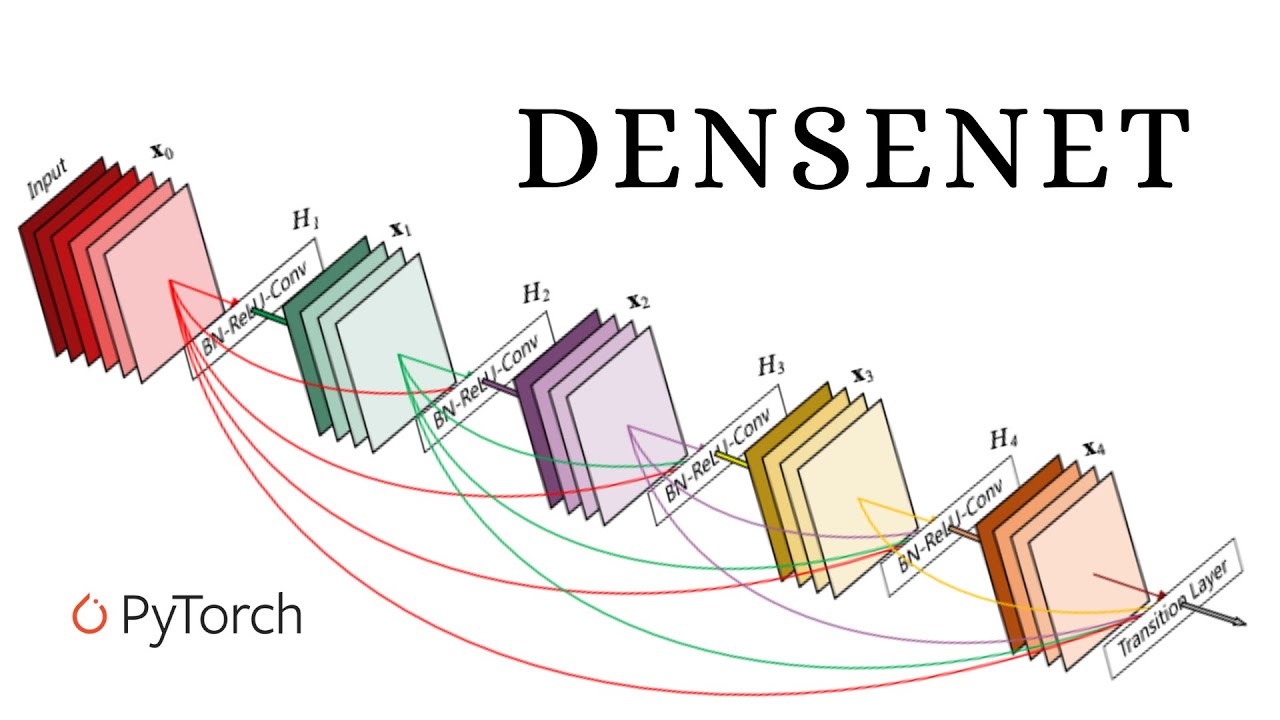
图 4-7 DenseNet
但这些创新要不就是基于 ResNet 思想的「精细化运营」,要不就过于局限于图像领域。在我心中 ResNet 是那个阶段最为瞩目的创新,也是它最为明显地为 Transformers 的诞生注入了灵魂的。我认为它配得上被称为是一颗洞穿神经网络深度大门的「制胜金球」。
今天,我们就用 ResNet 论文开头的那个数据集 CIFAR-10,重走一遍 ResNet 的来时路。让我们默颂着 PyTorch 魔法,踏出我们的宇宙飞船,忐忑着又期待的去领略 ResNet 温柔牵着我们的手逐渐深入的那个「深度」神经网络的漫漫良夜。
4.3 CIFAR-10¶
CIFAR 是 Canadian Institute for Advanced Research(加拿大高等研究院)的缩写,CIFAR-10 是由 Alex Krizhevsky 整理发布的 —— 没错,就是三年后写出 AlexNet 的那个 Alex。当时 Alex Krizhevsky 的老师是图灵奖及诺贝尔物理学奖得主 Geoffrey Hinton,他比较知名的贡献包括了多层神经网络中的反向传播、自监督学习和模型蒸馏。
Geoffrey Hinton 出身一个很有意思的家族。他的曾祖父乔治·布尔创立了布尔代数这门学科,我们常用的数据类型「布尔」就是他的名字。他的姑祖母艾捷尔·伏尼契是《牛虻》的作者,是我除儿童读物外读的第二本外国小说。不知道大家有没有在抖音或者 b 站上刷到过对外经贸大学计量经济学老师“阳和平”。阳和平的妈妈 Joan Hinto 是 Geoffrey Hinton 的堂姐。Joan Hinton 中国名字「寒春」,是伏尼契的孙女。寒春参与了小胖子原子弹的研制,是美国原子弹制造计划“曼哈顿工程”中少数的女科学家之一。26 岁时,她追随未婚夫来到中国延安。次年 1949 年在延安瓦窑堡的一个窑洞里成婚,然后就一直生活在中国。中国实施《外国人在中国永久居留审批管理办法》后,寒春是第一个获得中国“绿卡”的外国人。
扯得有点远…… 包括 Alex 在内,Geoffrey Hinton 有不少著名的学生,比如昨天我们提到过的 Yann LeCun。还有 OpenAI 四名初始创始人之一 Ilya Sutskever,他参与开发的 AlphaGo 在 2017 年因击败柯洁九段名声大噪。
他们贡献的 CIFAR-10 数据集后面的数字 10 是指这个数据集里的图像总共有 10 个完全互斥的日常物体类别。CIFAR-10 中的每个图片都是 32×32 的 RGB 彩色图像,共计 60000 张,下载下来 100 来兆,里面的图片大概长这样。

图 4-8 CIFAR-10
CIFAR 比几百吉(G)甚至上太(T)的 ImageNet 要小好几个数量级。但即使是以训练 ImageNet 为目标,先在 CIFAR 上对网络做一个快速的验证通常也会是个好主意。
4.3.1 下载数据集¶
Torch 就内置有 CIFAR-10 数据集,我们直接通过 Torch 把它下载到我们的磁盘上,指定放到相对路径 ./cifar10_data 下。这样我们下载一次之后,下次再用 Torch 就会自动检查这个路径下是否有已经下好的数据集,有下好的就不会重复下载了。
import numpy
import torch
import torchvision
import time
import random
train_set = torchvision.datasets.CIFAR10(root='./cifar10_data', train=True, download=True, transform=None)
test_set = torchvision.datasets.CIFAR10(root='./cifar10_data', train=False, download=True, transform=None)
CIFAR-10 是用 NumPy 存储的数据,它的维度是 (样本、图片高、图片宽、图片通道数)。Torch 更习惯的数据格式是 (样本、图片通道数、图片高、图片宽)。因此,我们用 Torch 的 .transpose 方法将 CIFAR-10 的数据维度映射一下。
train_data_np = train_set.data.transpose(0, 3, 1, 2)
test_data_np = test_set.data.transpose(0, 3, 1, 2)
然后,从这往后进入了深度神经网络,如果我们还用 CPU 来计算的话,一次训练的耗时将会以「天」来计算。我们把计算平台移动到 GPU 上,每次耗时将变成若干小时。
我们先准备一小段代码来侦测当前的机器上有什么样的 GPU。cuda 代表 Nvidia 或者 AMD 的显卡,mps 代表 macOS 平台的 Metal Performance Shaders。这个 mps 因为很多算子还没实现硬件级的加速,所以在模型训练时加速效果一般,推理时还行。要是这两个都没有侦测到,咱们就让 Torch 整体 fall back 回 CPU 计算。
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
print(f"Using device: {device}")
然后我们将我们的映射后的数据集给移动到显存里。
train_data = torch.tensor(train_data_np, device=device)
train_labels = torch.tensor(train_set.targets, dtype=torch.long, device=device)
test_data = torch.tensor(test_data_np, device=device)
test_labels = torch.tensor(test_set.targets, dtype=torch.long, device=device)
别忘了第 2 天我们没有做归一化,loss 起飞的事情。同样的方法,我们把全局归一化要用到的均值和标准差准备好,也都放显存里。
data = train_set.data.astype(np.float64) / 255.0
mean = torch.tensor(data.mean(axis=(0, 1, 2)), dtype=torch.float32).to(device)
std = torch.tensor(data.std(axis=(0, 1, 2)), dtype=torch.float32).to(device)
这样,我们的数据就基本准备好了。
4.3.2 卷积层¶
接下来,我们开始为组建我们的网络准备点必要的小零件。
第一个就是卷积层。如稍早时候所言,卷积就是各个维度相乘再相加。
前面我们已经把维度转换成了 (样本、图片通道数、图片高、图片宽)。通常人们习惯用 (N, C, H, W)来表达它们,我们也遵照惯例这样写。K 代表的是卷积核的 kernel。我们把各个维度分别存到这些变量里,利用 torch.nn.functional.unfold() 方法帮我们析出窗口滑动的每一个小矩阵,并把它们排成一列。然后我们使用 .permute() 方法交换维度,这样我们可以利用 GPU 的矩阵乘法一次并行算出所有的结果。最后使用 .permute() 方法还原旋转,利用 .view() 函数把维度还原回去。这样我们就实现了一个还算利用了点 GPU 的卷积层。
需要注意的是 C_out 和 C_in 是不同的。所谓「通道」,输入的通道指的是 RGB 三种颜色,但输出的通道数是由我们拿多少种卷积核去卷积它来决定的,即我们选择用多少种「看法」去观察这幅图。
def manual_conv2d(x, weight, stride=1, padding=0):
N, C_in, H_in, W_in = x.shape
C_out, _, K, _ = weight.shape # 需要注意的是 C_out 和 C_in 是不同的
H_out = (H_in + 2 * padding - K) // stride + 1
W_out = (W_in + 2 * padding - K) // stride + 1
x_unfolded = torch.nn.functional.unfold(x, kernel_size=K, stride=stride, padding=padding)
w_reshaped = weight.view(C_out, -1)
# out_unfolded = torch.einsum('cd, ndl -> ncl', w_reshaped, x_unfolded)
x_permuted = x_unfolded.permute(0, 2, 1) # (N, L, D) D = C_in*K*K
temp = torch.matmul(x_permuted, w_reshaped.T) # (N, L, C_out)
out_unfolded = temp.permute(0, 2, 1) # (N, C_out, L)
out = out_unfolded.view(N, C_out, H_out, W_out)
return out
4.3.3 参数初始化¶
上面 manual_conv2d() 函数的第二个参数 weight 便是卷积层的权重。
跟前几天一样,我们来给它申请点内存空间,顺便填点初始值进去。
def create_conv2d_param(in_channels, out_channels, kernel_size, device=None):
weight = torch.empty(out_channels, in_channels, kernel_size, kernel_size, device=device)
torch.nn.init.kaiming_normal_(weight, mode='fan_out', nonlinearity='relu')
return torch.nn.Parameter(weight)
可以看到,我们用了之前就用过的何恺明教授发明的恺明正则或称何氏初始化 torch.nn.init.kaiming_normal_() 来初始化了我们的权重。
反正都会梯度下降去慢慢学习,接近最优值的。如果我愿意多付出训练时间,能不能简单的把权重都初始化成 0 呢?
恐怕不行。

图 4-9 权重初始化为 0
我们考虑图 4-9 的网络。显然,它的前向推理式为下面的式子。
式 4-15 零初始化网络的前向计算式
设想现在我们 \(w_1\) 和 \(w_2\) 都一样是 0。那么,前向推理结束后我们得到一个 loss,然后往回求导,会发现导数是一样的。我们用 $ L$ 表示 loss,那么它们的梯度都是下面这个式子。
式 4-15 零初始化网络的梯度计算
它们得到了同样的梯度值。然后我们用同样的梯度去下降 \(w_1\) 和 \(w_2\),考虑到 \(w_1\) 和 \(w_2\) 本来就相等,所以反向传播结束时它俩会仍然保持一样的值。
这样循环往复,无论我们正向反向多少轮,我们会发现 \(w_1\) 和 \(w_2\) 总是会保持一致。
这便是所谓「权重的对称性问题」。
这让我想起一个笑话 —— 说小明工作了 10 年,但却只有 1 年的工作经验。因为他每年的工作内容都是一样的。
对称的网络权重就像这个笑话 —— 看似有 2 个权重参数,但是本质上它们合二为一了。本质上变成只有一个权重了,这样的退化,自然网络的表达力也不会正常。
那么,像第 2 天预测直播人数那样,我们把权重初始化为正态分布的、随机的、不同的值,行吗?
恐怕也不会得到很好的结果。
因为和第 2 天我们训练的单层神经网络不同的是,今天我们已经走到了「深度」神经网络。我们的梯度在从 loss 往回求导后,会经过倒数第一层、倒数第二层、倒数第三层这样一直往回传。
我们考虑这样一个最简单的 2 层网络。

图 4-10 最简单的 2 层网络
它的前向推理式为。
式 4-16 最简单的 2 层网络的前向推理式
那么,我们假定 loss 为 $ L $ ,对 $ w_1 $ 求导,来计算一下它的梯度。
式 4-17 最简单的 2 层网络的梯度计算
这个推导中出现的「分子」、「分母」出现能消的同样的数的推导方法,便是所谓「链式法则」。
我们可以看到,最终的结果中是要乘以 $ w_2 $ 的,即我们的权重会成为梯度的「因子」。
可以设想一下,如果我们的权重值的普遍小于 1 ,只要网络足够深,一直乘以这些小于 1 的权重。那么,梯度随着网络的加深就会越来越小,直至等于 0。这便是所谓「梯度消失」。
反之,如果权重值普遍大于 1,那么梯度就会越来越大,最终会浮点数溢出。这便是所谓「梯度爆炸」。
显然,「梯度消失」和「梯度爆炸」都不是我们希望看到的。所以,我们期望这些「因子」的乘积的期望近似等于 1。在满足正态分布的前提下再满足这个期望为 1 的初始化方法,就被称为 Xavier 初始化。
我们之前举的最简单的 2 层网络的例子没有考虑激活函数,其实梯度还会乘上激活函数的导数。我们考虑 ReLU 激活函数,会让负数等于0,即等价于干掉一半的参数。所以,为了满足 ReLU 激活函数,又要保持乘积的期望近似等于 1 torch.nn.init.kaiming_normal_() 就将 Xavier 初始化的方差放大了一倍,即将导数的期望翻倍了,以抵消 ReLU 激活函数的影响。
我们刚好是使用 ReLU,凯明初始化 torch.nn.init.kaiming_normal_() 正适合我们。
4.3.4 批量归一化¶
我不喜欢「批量归一化」这个翻译,「批量」这个词总给人一种一次处理大量数据的感觉。但事实恰恰相反,它一次处理的量很少,远不如之前我们做的「全局归一化」那么多。
「批量归一化」的英文是 Batch Normalization,通常简称为 BN。这里的 batch 指的是,我们常常因为显存不足以一次性装下所有训练数据,而把它们分成一小批、一小批地分别喂给 GPU 进行计算。每送一次,就叫一个 batch,而每次送进去的样本数量,通常称为 batch size。
Batch Normalization 实际上是在每一小批数据内部做归一化,归一化的范围远小于全局归一化。因此,我看到现在越来越多的资料开始把它翻译成「批归一化」。这个译法确实更贴近原意——强调“每批”内部的操作。
Batch Normalization 其实是在每次送数据的那一小批内部做归一化,归一化的范围是远小于全局归一化的。因此,我看现在越来越多的新的材料把它翻译成「批归一化」。
虽然「批归一化」在意思上准确得多,但「批」是一个短音节,紧跟着「归一化」这样一个长词,中间似缺少一个缓冲,读起来有种电车急起急停的晕车感。而且,「批」这个字在发音上是轻辅音加短元音,容易轻读,但它在意思上又很重要,不得不重读。这种冲突也让我纠结。要是大家能普遍接受「批次归一化」这个翻译就好了,我觉得它在准确性和发音流畅度上兼顾得最好。
「批量归一化」的想法和「全局归一化」是一样的,把所有的数据的分布拉到同一个尺度内,比如说均值为 0 方差为 1,让模型可以专心学习数据的特征,不用去适应数据的分布。其实就跟我们用卷积把「肯定存在的特征」预先给提取出去,在思想上是一样的。
所不同的是,「批归一化」不是在我们所有的样本数据上做这个「归一」操作,而是仅针对每次喂进 GPU 的「批次内」的这一小撮数据做归一。这样我们每次和每一个网络层归一拉的力度和方式都可以不一样,可以仅根据当前这一小撮数据表达更加精细而容易通过训练凸显的特征。可以想象的,当我们通过这样的方法把数据的特征给凸显出来,网络会学得更快,即更快收敛,且学不会的概率会降低,即训练得更加「稳定」,loss 起飞的概率更小。
def manual_batch_norm(x, running_mean, running_var, weight, bias, training=True, momentum=0.1):
N, C, H, W = x.shape
if training:
mean = x.mean(dim=(0, 2, 3))
var = x.var(dim=(0, 2, 3), unbiased=False)
with torch.no_grad():
running_mean.copy_(momentum * mean + (1 - momentum) * running_mean)
running_var.copy_(momentum * var + (1 - momentum) * running_var)
else:
mean = running_mean
var = running_var
mean = mean.view(1, C, 1, 1)
var = var.view(1, C, 1, 1)
weight = weight.view(1, C, 1, 1)
bias = bias.view(1, C, 1, 1)
x_normalized = (x - mean) * torch.rsqrt(var + 1e-05)
out = weight * x_normalized + bias
return out
相比「全局归一化」,这段代码中我们做出了三点改变。
-
使用
training参数把训练和推理时的批归一化的逻辑放一起了。 -
我们使用了方差
var替代了标准差std来计算归一化后的值。这是一个常见的优化。这样我们一方面可以使用上直接对应 GPU 硬件指令的torch.rsqrt()方法;另一方面又借助上了torch.rsqrt()这个指令算倒数的特性。同时,我们还能将除变乘,进一步加速运算。rsqrt()是一个比sqrt()更快的指令。
式 4-18 方差和标准差之间的关系
式 4-19 GPU 硬件指令 rsqrt() 的计算过程
由式 4-18 和式 4-19 可以看出,方差没做的开方 rsqrt() 给做了,顺手还做了一个由除转乘,且把这些代价全装进了一条硬件指令。快哉。
- 最后,在归一化之后,我们做了一个
out = weight * x_normalized + bias,这操作还花费了新增 2 个参数的代价。可是想想,归一化本身不就是先减再除吗?那我们现在搞个先乘再加,不就还原回去,白做了吗?
式 4-20 单个元素的归一化计算方法
不会白做的。想想残差模块,它是不是起到一个允许网络「不再学习」的角色?这个我们留下来的这两个乘数和加数参数也是同理。它们可以让网络自己决定它们的分布缩放和偏移多少是更好的,不一定非得是均值为 0 方差为 1 的缩放和偏移。实在不行,也允许网络完全在这一步彻底放弃归一化操作,保持它原来的值。
就像对孩子说,上学能学多少是多少,实在学不进去就玩!和残差模块一样,这里也能增强训练稳定性,稳住孩子的心神。最后获得加深网络深度的效果,从而让我们神经网络这个孩子的人生路能走得更远。批归一化是 2015 年由 Sergey Ioffe 和 Christian Szegedy 在 Google 提出,《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》于 2025 年获 ICML(国际机器学习大会) 时间检验奖(Test-of-Time Award)。
当然,我们也要准备一个函数为批归一化中的这两个参数进行初始化赋值。
def create_bn_param(num_features, device=None):
weight = torch.nn.Parameter(torch.ones(num_features, device=device))
bias = torch.nn.Parameter(torch.zeros(num_features, device=device))
running_mean = torch.zeros(num_features, device=device)
running_var = torch.ones(num_features, device=device)
return weight, bias, running_mean, running_var
我们再准备一个函数初始化全连接网络的参数,方法和昨天初始化多层神经网络参数的方法是一样的。
def create_linear_param(in_features, out_features, device=None):
weight = torch.empty(out_features, in_features, device=device)
torch.nn.init.kaiming_uniform_(weight, a=5 ** 0.5)
bias = torch.nn.Parameter(torch.zeros(out_features, device=device))
return torch.nn.Parameter(weight), bias
4.3.5 残差模块¶
好。我们小零件足够我们来拼装 ResNet 最核心的那个大零件 残差模块 了。
我们参照 ResNet 论文中的这幅图中左侧的那个较为简单的实现,来构建我们的残差模块。
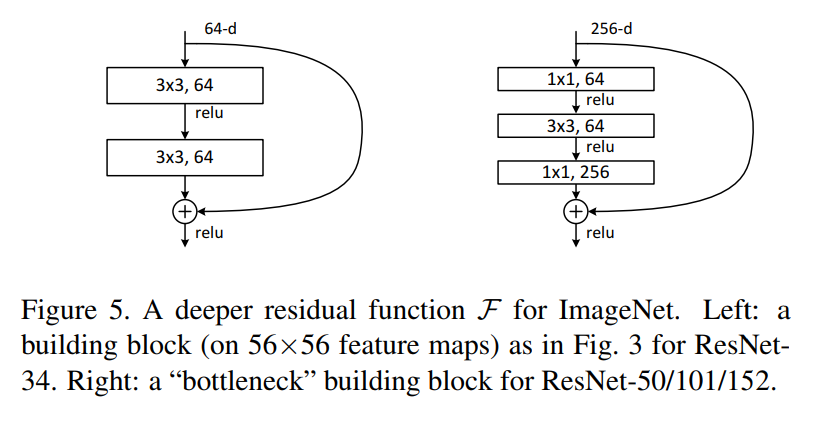
图 4-11 残差模块的具体实现
图 4-11 实际是图 4-4 的具像化,从中我们可以看到图 4-4 的上下两个 weight layer 实际是两个卷积层。这个我们前面已经实现过了。中间夹了一个 ReLU,我们之前也实现过了,这次我们就直接用 Torch 内置的版本。图上没画出来的还有,每个卷积层后面都还跟着一个批归一化层。
以上的零件我们都已经实现好了。把这些都拼好,那么最后就剩最关键的 —— 残差 —— 其实就是简单一加。咱们的残差模块就 OK 了。
def residual_block(x, layer_name, block_idx, stride, weights, is_training):
"""
残差模块的前向计算
x: 输入张量
layer_name: 层名,如 'layer1', 'layer2'
block_idx: 块索引,0 或 1
stride: 卷积步长
weights: 包含所有参数的字典
is_training: 是否为训练模式(bool)
"""
identity = x
# Conv1
out = manual_conv2d(x, weights[f'{layer_name}_b{block_idx}_conv1_w'], stride=stride, padding=1)
out = manual_batch_norm(out,
weights[f'{layer_name}_b{block_idx}_bn1_rm'],
weights[f'{layer_name}_b{block_idx}_bn1_rv'],
weights[f'{layer_name}_b{block_idx}_bn1_w'],
weights[f'{layer_name}_b{block_idx}_bn1_b'],
training=is_training)
out = torch.nn.functional.relu(out)
# Conv2
out = manual_conv2d(out, weights[f'{layer_name}_b{block_idx}_conv2_w'], stride=1, padding=1)
out = manual_batch_norm(out,
weights[f'{layer_name}_b{block_idx}_bn2_rm'],
weights[f'{layer_name}_b{block_idx}_bn2_rv'],
weights[f'{layer_name}_b{block_idx}_bn2_w'],
weights[f'{layer_name}_b{block_idx}_bn2_b'],
training=is_training)
# Shortcut
if f'{layer_name}_b{block_idx}_sc_w' in weights:
identity = manual_conv2d(identity, weights[f'{layer_name}_b{block_idx}_sc_w'], stride=stride, padding=0)
identity = manual_batch_norm(identity,
weights[f'{layer_name}_b{block_idx}_sc_bn_rm'],
weights[f'{layer_name}_b{block_idx}_sc_bn_rv'],
weights[f'{layer_name}_b{block_idx}_sc_bn_w'],
weights[f'{layer_name}_b{block_idx}_sc_bn_b'],
training=is_training)
out += identity # 这里便是所谓的「残差」
out = torch.nn.functional.relu(out)
return out
可以看到,这段函数就是 2 个卷积和批归一化之间夹着一个 ReLU,最后追加一个加法,然后再一个 ReLU,便结束了。
这个函数看上去稍微有点复杂的原因是,由于层有点多,所以导致权重参数也有点多。我们想要把所有的权重都装到一个字典变量 weights 中,方便未来送给 Torch 的 SGD 去自动下降。所以那些看着晃眼的部分其实都是这个字典的key,我们为了把各个层所必须的各个权重都放在一起区分开用的。
还有一个看起来可能有点疑惑的地方是在最后加残差之前多出了一个 if 。这个 if 是一个 1x1 的卷积层。做这个卷积的目的是让,如果 identity 和 out 维度不相同导致无法相加时,把它们的维度变一致,从而使得 out += identity 成为可能。
在我们深入 1x1 卷积核之前,我们先把残差模块的参数初始化函数准备好。
def initialize_residual_block_weights(weights, layer_name, block_idx, in_ch, out_ch, has_shortcut, device):
"""
向 weights 字典中添加一个残差块的所有参数
"""
# Conv1
weights[f'{layer_name}_b{block_idx}_conv1_w'] = create_conv2d_param(in_ch, out_ch, 3, device=device)
w, b, rm, rv = create_bn_param(out_ch, device=device)
weights[f'{layer_name}_b{block_idx}_bn1_w'], weights[f'{layer_name}_b{block_idx}_bn1_b'] = w, b
weights[f'{layer_name}_b{block_idx}_bn1_rm'], weights[f'{layer_name}_b{block_idx}_bn1_rv'] = rm, rv
# Conv2
weights[f'{layer_name}_b{block_idx}_conv2_w'] = create_conv2d_param(out_ch, out_ch, 3, device=device)
w, b, rm, rv = create_bn_param(out_ch, device=device)
weights[f'{layer_name}_b{block_idx}_bn2_w'], weights[f'{layer_name}_b{block_idx}_bn2_b'] = w, b
weights[f'{layer_name}_b{block_idx}_bn2_rm'], weights[f'{layer_name}_b{block_idx}_bn2_rv'] = rm, rv
# Shortcut (if needed)
if has_shortcut:
weights[f'{layer_name}_b{block_idx}_sc_w'] = create_conv2d_param(in_ch, out_ch, 1, device=device)
w, b, rm, rv = create_bn_param(out_ch, device=device)
weights[f'{layer_name}_b{block_idx}_sc_bn_w'], weights[f'{layer_name}_b{block_idx}_sc_bn_b'] = w, b
weights[f'{layer_name}_b{block_idx}_sc_bn_rm'], weights[f'{layer_name}_b{block_idx}_sc_bn_rv'] = rm, rv
能看到,参数模块的初始化方法为 2 个卷积加批归一化层调用了 2 次卷积初始化和批归一化的初始化方法。然后,和残差模块一样,拐出来一个if 。这个 if 中,传递给 create_conv2d_param() 函数的 kernel_size 的参数的值为 1, 这便是在为我们 1x1 的卷积层在初始化参数。接下来我们就来深入看看 1x1 卷积层它是怎么在工作的。
4.3.6 1x1 卷积层¶
首先,我们肯定知道两个矩阵需要维度一致才能相加。
式 4-21 两个无法相加的矩阵
那么,为什么有些时候式 4-14 中的 $ \mathcal{F}(\mathbf{x}, {W_i}) $ 和 $ \mathbf{x} $ ,即残差模块的两个加数会维度不一致呢?
回忆一下,残差是把进入神经网络的输入值和经过神经网络的输出相加。不一致即是指这两个家伙不一致。
那么,经过卷积的输出为什么和输入维度不一致呢?有 2 个可能的原因。
-
当我们用多个卷积核对图像进行卷积时,每个卷积核都会生成它自己的一个结果,也就是一个特征图。每个特征图即一个维度。卷积核的数量是自由选择的,如果卷积核的数量不等于输入的维度,那么输出的维度就会和输入维度不一致。
-
我们的卷积是把一个像素和它周围的像素一起计算得出结果,所以实际计算完,如果不经处理,图像实际是缩小了。我们对比式 4-3 和式 4-11 也能直观的观察到这个现象。
所以,1x1 卷积核是怎么把维度改回一致的呢?
其实,我们应该敏感的感受到一个问题:用 1x1 的卷积核去操作,那这个操作还算是「卷积」吗?—— 卷积不是若干个像素一起操作吗?1x1 就剩我自己了,我和谁去卷去?
答案是和输入矩阵中的其它通道的同位置的那些像素去卷。
比如说我们有一个 RGB 3 通道的输入图像。1 个 1x1 的卷积核,它的第一次计算是把 x=0,y=0 的 R 像素、x=0,y=0 的 G 像素、x=0,y=0 的 B 像素这 3 个值拿来卷了。可以想象,完成整个的卷积计算后,它实质是把 3 个通道给合并了,得到一个单通道的图片的输出。通过这种方法,1x1 的卷积可以接收任意通道数的输入,并全给转成单通道。

图 4-12 1x1 卷积将 3 通道合并为 1 通道
输入任意通道搞定了,那么,怎么能做到输出任意通道呢?简单。1 个卷积核得到一个通道,想要几个通道的输出,就整几个不同的卷积核去卷,就能得到几个通道了。
很好,一切都清楚了。但,请打住一下!你还记得我们折腾卷积的「初心」是什么吗?
是我们想告诉网络,一个像素是和它周围的像素共同一起组成意义的。
其实,再想想,如果我们用 1x1 的卷积核,把每个像素都单独拉出来,那不是就违背了我们卷积的「初心」了?那卷积层不是就退化成我们之前的线性层了。
其实我们可以简单的理解 1x1 卷积层就是相当于退化成了线性层。就像昨天我们用一个线性层把 784 维转 512 维一样,线性层当然是可以轻松写意地做任意的维度转换的啦。乘以一个矩阵就行了,矩阵相乘相加就是和 1x1 卷积的加权求和等价的。

图 4-13 线性层可以实现任意的维度转换
4.3.7 ResNet-18¶
ResNet 在论文中提出了从 18 到 1000+ 的各种层数的网络,对于我们今天的 CIFAR-10 任务而言,最浅的 ResNet-18 就已经够用。
咱们一个残差模块里有 2 个卷积层和 2 个批归一化层,总共就 4 层。所以我们用 4 个残差模块就已经 16 层了。然后头上加一个初始化卷积帮我们把原始图像的 RGB 3 通道特征提取出 64 个通道,让后续的残差块能从足够丰富的角度去理解图片。最后尾巴上加一个全连接层帮忙输出最后的 10 个分类的概率,这便是我们的 18 层 ResNet 了。
def resnet18(x, weights, is_training):
"""
ResNet-18 前向计算
x: 输入张量
weights: 包含所有参数的字典
is_training: 是否为训练模式(bool)
"""
out = manual_conv2d(x, weights['conv1_w'], stride=1, padding=1)
out = manual_batch_norm(out,
weights['bn1_rm'], weights['bn1_rv'],
weights['bn1_w'], weights['bn1_b'],
training=is_training)
out = torch.nn.functional.relu(out)
# Layer 1
out = residual_block(out, 'layer1', 0, 1, weights, is_training)
out = residual_block(out, 'layer1', 1, 1, weights, is_training)
# Layer 2
out = residual_block(out, 'layer2', 0, 2, weights, is_training)
out = residual_block(out, 'layer2', 1, 1, weights, is_training)
# Layer 3
out = residual_block(out, 'layer3', 0, 2, weights, is_training)
out = residual_block(out, 'layer3', 1, 1, weights, is_training)
# Layer 4
out = residual_block(out, 'layer4', 0, 2, weights, is_training)
out = residual_block(out, 'layer4', 1, 1, weights, is_training)
out = manual_avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = torch.nn.functional.linear(out, weights['fc_w'], weights['fc_b'])
return out
可以观察到,在最后送进全连接层之前,我们调用了一个 manual_avg_pool2d() 这个函数。正如其名,这个函数名唤pool「池」化,前面的 avg 是平均的缩写。所以,我们在最后分 10 类之前,把数据送进了一个 平均池化层。我们暂且放放它。先把 ResNet-18 的权重初始化函数写好,再回头展开这个平均池化。
def initialize_weights(device):
weights = {}
weights['conv1_w'] = create_conv2d_param(3, 64, 3, device=device)
w, b, rm, rv = create_bn_param(64, device=device)
weights['bn1_w'], weights['bn1_b'] = w, b
weights['bn1_rm'], weights['bn1_rv'] = rm, rv
# Layer1 (64 channels, both blocks stride=1, no shortcut)
initialize_residual_block_weights(weights, 'layer1', 0, 64, 64, False, device)
initialize_residual_block_weights(weights, 'layer1', 1, 64, 64, False, device)
# Layer2 (first block: 64->128, stride=2, shortcut; second: 128->128, stride=1, no shortcut)
initialize_residual_block_weights(weights, 'layer2', 0, 64, 128, True, device)
initialize_residual_block_weights(weights, 'layer2', 1, 128, 128, False, device)
# Layer3 (first block: 128->256, stride=2, shortcut; second: 256->256, stride=1)
initialize_residual_block_weights(weights, 'layer3', 0, 128, 256, True, device)
initialize_residual_block_weights(weights, 'layer3', 1, 256, 256, False, device)
# Layer4 (first block: 256->512, stride=2, shortcut; second: 512->512, stride=1)
initialize_residual_block_weights(weights, 'layer4', 0, 256, 512, True, device)
initialize_residual_block_weights(weights, 'layer4', 1, 512, 512, False, device)
# Fully connected layer
fc_w, fc_b = create_linear_param(512, 10, device=device)
weights['fc_w'], weights['fc_b'] = fc_w, fc_b
return weights
这个函数没有什么特别的,可以看到最后我们的线性层输出参数为 10,那就是我们准备的 10 个分类的概率值。
4.3.8 池化¶
想想,在今天引入「池化」之前,昨天的我们是怎么做的呢?
我们把神经网络最后一层的结果,连上一个我们需要分类数目的单层神经网络,然后就得出了每个种类的概率值。
事实上,我们开始做这件事的目的逼迫着我们和我们的网络,不管之前的层学到了多少维度的特征,把对目标的理解深挖到了什么程度,到了最后,这些理解都必须坍塌到我们赋予它的目的上。网络在那些中间层里也许学到了苹果是圆的、香蕉是黄色的、桌子是棱角分明的、人脸是有 2 个眼睛的……不管这样的维度有多少,最后一步都得把这些展开的高维度给映射到分 10 类这个简单的低维空间上。
也就是「降维」。
那么,「池化」是一个什么样的操作呢?
式 4-22 平均池化
池化操作和卷积一样,弄一个小框,框进一部分像素,对这部分像素求均值,然后填到结果矩阵中。重复这个过程,直到结果矩阵被填满。由于输入矩阵的多个值才能平均出结果矩阵的一个值,所以结果矩阵的尺寸肯定是比输入矩阵的小。
所以,可以看出,池化其实做的也是降维。我们可以这样理解,对于图像的像素是和周围的像素联合组成意义这个特点,全连接理论上都能学会,但卷积是提取特征这件事的特化,而池化则是在降维这件事的特化。
def manual_avg_pool2d(x, kernel_size, stride=None, padding=0):
N, C, H, W = x.shape
if stride is None:
stride = kernel_size
# 计算输出尺寸
H_out = (H + 2 * padding - kernel_size) // stride + 1
W_out = (W + 2 * padding - kernel_size) // stride + 1
# 对输入进行 padding
if padding > 0:
x = torch.nn.functional.pad(x, (padding, padding, padding, padding), mode='constant', value=0)
# 使用 unfold 提取滑动窗口
x_unfolded = torch.nn.functional.unfold(x, kernel_size, stride=stride, padding=0)
# x_unfolded shape: (N, C*K*K, L)
L = x_unfolded.size(2)
# 变形为 (N, C, K*K, L) 并求平均
x_unfolded = x_unfolded.view(N, C, kernel_size * kernel_size, L)
out_unfolded = x_unfolded.mean(dim=2) # (N, C, L)
# 变形回图像形状
out = out_unfolded.view(N, C, H_out, W_out)
return out
从代码中可以看出,池化和卷积一样,都是以 torch.nn.functional.unfold() 方法为核心,一次性得到所有滑动窗口,而后并行计算得出结果的。
池化分两种「平均池化」和「最大池化」。顾名思义,平均池化就是把框进来的每个值加一起求均值放到结果里,而最大池化就是把框进来的每个值中的最大值放到结果里。
式 4-23 最大池化
很简单对不,那么它们的实际效果区别是什么呢?最大池化会留下最重要的信息,其它的信息直接丢弃,换言之,它会丢掉细节。而平均池化更倾向于认为每个信息都是有价值的。所以,在使用它们时,通常最大池化会处于网络的前端,对于输入图像做一个类似降噪的效果,而平均池化会处于网络的后端,因为这时的图像已经经过前面的很多层提取特征,每个特征都蕴含了那些层的劳动和心血。
具体在我们的实现中,我们使用的这个平均池化就处于整个网络的最后端,再往后就得分类了,不能再后了。
4.3.9 数据正则化¶
网络已经 OK。还差最后一步,我们就开始训练。
训练之前,我们还希望对数据做一个名唤「正则化」的预处理。
「正则」并不是我们日常会使用的中文词,是个让人有点疑惑的名字。上一次听到它,还是在「正则表达式」这个词里。
什么是正则表达式呢?我们都知道那就是一个字符串规则,用以匹配任意符合这个规则的字符串。就好比字符串 abc123 就是符合 [a-z]{3}[0-9]{3} 这个正则表达式的。
我们可以说,[a-z]{3}[0-9]{3} 其实表达了所有形如 abc123 的字符串的所谓 内在规律。
没错,这也是我们希望大模型做到的事。
所谓「正则」,我们可以理解「则」为规则、规律,「正」为使之符合。合起来「正则化」就是使得某物暗合某种规则规律。
它的反面是我们之前说过的「过拟合」,即记住了每个特例,而忘记了背后的普遍规律、规则。
那么我们要「正则化」的对象是谁呢?
虽然我们目前要处理的是输入数据,但是我们肯定希望掌握规律的是训练出来的大模型。对于数据而言,我们反而要让它破损、缺失、模糊。就如同我们之前看到的 AlexNet 的 DropOut,那也是正则化的方法之一。它就是通过丢掉一些权重,挡住一些书页的办法,让模型无法直接记忆特例,从而被迫去理解规律。
在我们这个例子中,我们准备对输入的图像先随机裁剪掉一部分,然后将一半的图像做一个水平翻转。我们希望通过这样的正则化处理,最终我们的模型正着看,倒着看,看上半部分,看下半部分,都能认出苹果就是苹果。
def train_preprocess(img_tensor, mean, std):
# 四边都加上 4 个像素的黑边,将我们的 32x32 的图像变成 40x40
img = torchvision.transforms.functional.pad(img_tensor, padding=4, fill=0)
# 随机裁剪回 32x32
top = random.randint(0, 8)
left = random.randint(0, 8)
img = torchvision.transforms.functional.crop(img, top, left, 32, 32)
# 将一半的图像水平翻转
if random.random() < 0.5:
img = torchvision.transforms.functional.hflip(img)
# 归一化(标准化)
img = img.float() / 255.0
img = (img - mean.view(3, 1, 1)) / std.view(3, 1, 1)
return img
在我们这个预处理函数中,我们不仅做了正则化,把必须要做的全局归一化也放进去做了。
顺手的,我们把测试需要用的预处理函数也写出来。测试用的预处理就看全图了,做题的时候就不用给模型制造障碍了。我们就把全局归一化做了就好了。
def test_preprocess(img_tensor, mean, std):
img = img_tensor.float() / 255.0
img = (img - mean.view(3, 1, 1)) / std.view(3, 1, 1)
return img
4.3.10 开始训练¶
数据、网络都齐备了。还差 Loss 和优化器。这两个我们就用之前已经实现过的交叉熵损失 torch.nn.functional.cross_entropy() 和随机梯度下降法 torch.optim.SGD() 就好。如果忘记了它们的内部实现,现在是个往回翻翻,复习的好时机。
接下来我们就分批分次把我的训练数据喂进网络去让它学起来。
def train(weights, optimizer, train_data, train_labels, batch_size, device, mean, std):
weights = {k: v for k, v in weights.items()} # ensure we work on the dict
num_samples = len(train_labels)
indices = list(range(num_samples))
random.shuffle(indices)
total_loss = 0.0
total_correct = 0
total_batches = 0
for i in range(0, num_samples, batch_size):
batch_indices = indices[i:i+batch_size]
batch_images = train_data[batch_indices] # raw uint8 images, shape (B, C, H, W)
batch_labels = train_labels[batch_indices]
# 正则化
preprocessed = []
for img in batch_images:
# img is a uint8 tensor on device, shape (C, H, W)
img = train_preprocess(img, mean, std) # uses random crop & flip
preprocessed.append(img)
batch_x = torch.stack(preprocessed, dim=0).to(device)
logits = resnet18(batch_x, weights, is_training=True)
loss = torch.nn.functional.cross_entropy(logits, batch_labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * len(batch_indices)
total_correct += (torch.argmax(logits, dim=1) == batch_labels).sum().item()
total_batches += 1
avg_loss = total_loss / num_samples
accuracy = total_correct / num_samples * 100.0
return avg_loss, accuracy
一个问题。我们分批次把数据喂给网络是为什么呢?为什么要分批次喂?
当然,显存有限,放不下所有的训练数据肯定是一个 solid 的原因。
但是如果我们需要训练的数据集足够小,或者显存很大,咱就不经思考地把所有数据一次喂给网络吗?
答案恐怕不总是肯定的。
想想,我们之前做正则化,其实是把训练数据「挡住一部分」,从而期望「正」我们网络的「则」。那如果我们每次权重的梯度下降都是基于所有的训练数据的 Loss 来做的,那不就又走到正则的反面了么?事实上,那样确实就会存在过拟合的隐患。所以,即使放得下,我们也得慎重考虑一次性给进去所有数据的做法。
然后我们把测试集的函数也写一下。和训练函数一样,它返回一个在整个数据集上预测的准确度。
def test(weights, test_data, test_labels, batch_size, device, mean, std):
weights = {k: v for k, v in weights.items()}
num_samples = len(test_labels)
total_correct = 0
for i in range(0, num_samples, batch_size):
batch_images = test_data[i:i+batch_size]
batch_labels = test_labels[i:i+batch_size]
# Apply test preprocessing (only normalisation, no random transforms)
preprocessed = []
for img in batch_images:
img = test_preprocess(img, mean, std)
preprocessed.append(img)
batch_x = torch.stack(preprocessed, dim=0).to(device)
with torch.no_grad():
logits = resnet18(batch_x, weights, is_training=False)
total_correct += (torch.argmax(logits, dim=1) == batch_labels).sum().item()
accuracy = total_correct / num_samples * 100.0
return accuracy
所有的碎片终于都集齐了!我们来组合我们的主函数。
if __name__ == '__main__':
EPOCHS = 100
BATCH_SIZE = 128
LEARNING_RATE = 0.01
TRAIN_ACC_THRESHOLD = 90.0
SGD_MOMENTUM = 0.9
WEIGHT_DECAY = 1e-4
train_set = torchvision.datasets.CIFAR10(root='./cifar10_data', train=True, download=True, transform=None)
test_set = torchvision.datasets.CIFAR10(root='./cifar10_data', train=False, download=True, transform=None)
train_data_np = train_set.data.transpose(0, 3, 1, 2)
test_data_np = test_set.data.transpose(0, 3, 1, 2)
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
print(f"Using device: {device}")
train_data = torch.tensor(train_data_np, device=device)
train_labels = torch.tensor(train_set.targets, dtype=torch.long, device=device)
test_data = torch.tensor(test_data_np, device=device)
test_labels = torch.tensor(test_set.targets, dtype=torch.long, device=device)
data = train_set.data.astype(numpy.float64) / 255.0
mean = torch.tensor(data.mean(axis=(0, 1, 2)), dtype=torch.float32).to(device)
std = torch.tensor(data.std(axis=(0, 1, 2)), dtype=torch.float32).to(device)
weights = initialize_weights(device)
trainable_params = []
# running_mean 和 running_var 不是 torch.nn.Parameter,我们要把它俩拿掉
for name, param in weights.items():
if isinstance(param, torch.nn.Parameter):
trainable_params.append(param)
optimizer = torch.optim.SGD(trainable_params, lr=LEARNING_RATE,
momentum=SGD_MOMENTUM, weight_decay=WEIGHT_DECAY)
for epoch in range(1, EPOCHS + 1):
start_time = time.time()
train_loss, train_acc = train(weights, optimizer,
train_data, train_labels,
BATCH_SIZE, device, mean, std)
epoch_time = time.time() - start_time
print(f"Epoch {epoch:2d}: TrainTime = {epoch_time:.2f}s, "
f"TrainLoss = {train_loss:.4f}, TrainAcc = {train_acc:.2f}%", end=' ')
if train_acc >= TRAIN_ACC_THRESHOLD:
test_acc = test(weights, test_data, test_labels,
BATCH_SIZE, device, mean, std)
print(f"TestAcc = {test_acc:.2f}%")
else:
print()
我们训练了 100 趟,或者说得洋气点,训了 100 个 epoch。为节约一点 GPU 时间,我们在训练集的准确度达到 90% 之后,才开始在测试集上尝试测量准确度。
4.3.11 全部收拢¶
今天的代码片段有点多。我把上面的代码片段收拢了一下,汇聚成一个完整的程序,方便我们开始训练。
也让我们有个流畅的代码观览体验,在托付给 GPU 执行之前再整体读一遍这个 ResNet 的实现。看看还有哪里不合理或者不理解、不熟悉的地方。
import numpy
import torch
import torchvision
import time
import random
def manual_conv2d(x, weight, stride=1, padding=0):
N, C_in, H_in, W_in = x.shape
C_out, _, K, _ = weight.shape # 需要注意的是 C_out 和 C_in 是不同的
H_out = (H_in + 2 * padding - K) // stride + 1
W_out = (W_in + 2 * padding - K) // stride + 1
x_unfolded = torch.nn.functional.unfold(x, kernel_size=K, stride=stride, padding=padding)
w_reshaped = weight.view(C_out, -1)
# out_unfolded = torch.einsum('cd, ndl -> ncl', w_reshaped, x_unfolded)
x_permuted = x_unfolded.permute(0, 2, 1) # (N, L, D) D = C_in*K*K
temp = torch.matmul(x_permuted, w_reshaped.T) # (N, L, C_out)
out_unfolded = temp.permute(0, 2, 1) # (N, C_out, L)
out = out_unfolded.view(N, C_out, H_out, W_out)
return out
def manual_avg_pool2d(x, kernel_size, stride=None, padding=0):
N, C, H, W = x.shape
if stride is None:
stride = kernel_size
# 计算输出尺寸
H_out = (H + 2 * padding - kernel_size) // stride + 1
W_out = (W + 2 * padding - kernel_size) // stride + 1
# 对输入进行 padding
if padding > 0:
x = torch.nn.functional.pad(x, (padding, padding, padding, padding), mode='constant', value=0)
# 使用 unfold 提取滑动窗口
x_unfolded = torch.nn.functional.unfold(x, kernel_size, stride=stride, padding=0)
# x_unfolded shape: (N, C*K*K, L)
L = x_unfolded.size(2)
# 变形为 (N, C, K*K, L) 并求平均
x_unfolded = x_unfolded.view(N, C, kernel_size * kernel_size, L)
out_unfolded = x_unfolded.mean(dim=2) # (N, C, L)
# 变形回图像形状
out = out_unfolded.view(N, C, H_out, W_out)
return out
def create_conv2d_param(in_channels, out_channels, kernel_size, device=None):
weight = torch.empty(out_channels, in_channels, kernel_size, kernel_size, device=device)
torch.nn.init.kaiming_normal_(weight, mode='fan_out', nonlinearity='relu')
return torch.nn.Parameter(weight)
def manual_batch_norm(x, running_mean, running_var, weight, bias, training=True, momentum=0.1):
N, C, H, W = x.shape
if training:
mean = x.mean(dim=(0, 2, 3))
var = x.var(dim=(0, 2, 3), unbiased=False)
with torch.no_grad():
running_mean.copy_(momentum * mean + (1 - momentum) * running_mean)
running_var.copy_(momentum * var + (1 - momentum) * running_var)
else:
mean = running_mean
var = running_var
mean = mean.view(1, C, 1, 1)
var = var.view(1, C, 1, 1)
weight = weight.view(1, C, 1, 1)
bias = bias.view(1, C, 1, 1)
x_normalized = (x - mean) * torch.rsqrt(var + 1e-05)
out = weight * x_normalized + bias
return out
def create_bn_param(num_features, device=None):
weight = torch.nn.Parameter(torch.ones(num_features, device=device))
bias = torch.nn.Parameter(torch.zeros(num_features, device=device))
running_mean = torch.zeros(num_features, device=device)
running_var = torch.ones(num_features, device=device)
return weight, bias, running_mean, running_var
def create_linear_param(in_features, out_features, device=None):
weight = torch.empty(out_features, in_features, device=device)
torch.nn.init.kaiming_uniform_(weight, a=5 ** 0.5)
bias = torch.nn.Parameter(torch.zeros(out_features, device=device))
return torch.nn.Parameter(weight), bias
def residual_block(x, layer_name, block_idx, stride, weights, is_training):
"""
残差模块的前向计算
x: 输入张量
layer_name: 层名,如 'layer1', 'layer2'
block_idx: 块索引,0 或 1
stride: 卷积步长
weights: 包含所有参数的字典
is_training: 是否为训练模式(bool)
"""
identity = x
# Conv1
out = manual_conv2d(x, weights[f'{layer_name}_b{block_idx}_conv1_w'], stride=stride, padding=1)
out = manual_batch_norm(out,
weights[f'{layer_name}_b{block_idx}_bn1_rm'],
weights[f'{layer_name}_b{block_idx}_bn1_rv'],
weights[f'{layer_name}_b{block_idx}_bn1_w'],
weights[f'{layer_name}_b{block_idx}_bn1_b'],
training=is_training)
out = torch.nn.functional.relu(out)
# Conv2
out = manual_conv2d(out, weights[f'{layer_name}_b{block_idx}_conv2_w'], stride=1, padding=1)
out = manual_batch_norm(out,
weights[f'{layer_name}_b{block_idx}_bn2_rm'],
weights[f'{layer_name}_b{block_idx}_bn2_rv'],
weights[f'{layer_name}_b{block_idx}_bn2_w'],
weights[f'{layer_name}_b{block_idx}_bn2_b'],
training=is_training)
# Shortcut
if f'{layer_name}_b{block_idx}_sc_w' in weights:
identity = manual_conv2d(identity, weights[f'{layer_name}_b{block_idx}_sc_w'], stride=stride, padding=0)
identity = manual_batch_norm(identity,
weights[f'{layer_name}_b{block_idx}_sc_bn_rm'],
weights[f'{layer_name}_b{block_idx}_sc_bn_rv'],
weights[f'{layer_name}_b{block_idx}_sc_bn_w'],
weights[f'{layer_name}_b{block_idx}_sc_bn_b'],
training=is_training)
out += identity
out = torch.nn.functional.relu(out)
return out
def resnet18(x, weights, is_training):
"""
ResNet-18 前向计算
x: 输入张量
weights: 包含所有参数的字典
is_training: 是否为训练模式(bool)
"""
out = manual_conv2d(x, weights['conv1_w'], stride=1, padding=1)
out = manual_batch_norm(out,
weights['bn1_rm'], weights['bn1_rv'],
weights['bn1_w'], weights['bn1_b'],
training=is_training)
out = torch.nn.functional.relu(out)
# Layer 1
out = residual_block(out, 'layer1', 0, 1, weights, is_training)
out = residual_block(out, 'layer1', 1, 1, weights, is_training)
# Layer 2
out = residual_block(out, 'layer2', 0, 2, weights, is_training)
out = residual_block(out, 'layer2', 1, 1, weights, is_training)
# Layer 3
out = residual_block(out, 'layer3', 0, 2, weights, is_training)
out = residual_block(out, 'layer3', 1, 1, weights, is_training)
# Layer 4
out = residual_block(out, 'layer4', 0, 2, weights, is_training)
out = residual_block(out, 'layer4', 1, 1, weights, is_training)
# 替换为手动实现的平均池化
out = manual_avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = torch.nn.functional.linear(out, weights['fc_w'], weights['fc_b'])
return out
def train_preprocess(img_tensor, mean, std):
img = torchvision.transforms.functional.pad(img_tensor, padding=4, fill=0)
top = random.randint(0, 8)
left = random.randint(0, 8)
img = torchvision.transforms.functional.crop(img, top, left, 32, 32)
if random.random() < 0.5:
img = torchvision.transforms.functional.hflip(img)
img = img.float() / 255.0
img = (img - mean.view(3, 1, 1)) / std.view(3, 1, 1)
return img
def test_preprocess(img_tensor, mean, std):
img = img_tensor.float() / 255.0
img = (img - mean.view(3, 1, 1)) / std.view(3, 1, 1)
return img
def initialize_residual_block_weights(weights, layer_name, block_idx, in_ch, out_ch, has_shortcut, device):
"""
向 weights 字典中添加一个残差块的所有参数
"""
# Conv1
weights[f'{layer_name}_b{block_idx}_conv1_w'] = create_conv2d_param(in_ch, out_ch, 3, device=device)
w, b, rm, rv = create_bn_param(out_ch, device=device)
weights[f'{layer_name}_b{block_idx}_bn1_w'], weights[f'{layer_name}_b{block_idx}_bn1_b'] = w, b
weights[f'{layer_name}_b{block_idx}_bn1_rm'], weights[f'{layer_name}_b{block_idx}_bn1_rv'] = rm, rv
# Conv2
weights[f'{layer_name}_b{block_idx}_conv2_w'] = create_conv2d_param(out_ch, out_ch, 3, device=device)
w, b, rm, rv = create_bn_param(out_ch, device=device)
weights[f'{layer_name}_b{block_idx}_bn2_w'], weights[f'{layer_name}_b{block_idx}_bn2_b'] = w, b
weights[f'{layer_name}_b{block_idx}_bn2_rm'], weights[f'{layer_name}_b{block_idx}_bn2_rv'] = rm, rv
# Shortcut (if needed)
if has_shortcut:
weights[f'{layer_name}_b{block_idx}_sc_w'] = create_conv2d_param(in_ch, out_ch, 1, device=device)
w, b, rm, rv = create_bn_param(out_ch, device=device)
weights[f'{layer_name}_b{block_idx}_sc_bn_w'], weights[f'{layer_name}_b{block_idx}_sc_bn_b'] = w, b
weights[f'{layer_name}_b{block_idx}_sc_bn_rm'], weights[f'{layer_name}_b{block_idx}_sc_bn_rv'] = rm, rv
def initialize_weights(device):
weights = {}
weights['conv1_w'] = create_conv2d_param(3, 64, 3, device=device)
w, b, rm, rv = create_bn_param(64, device=device)
weights['bn1_w'], weights['bn1_b'] = w, b
weights['bn1_rm'], weights['bn1_rv'] = rm, rv
# Layer1 (64 channels, both blocks stride=1, no shortcut)
initialize_residual_block_weights(weights, 'layer1', 0, 64, 64, False, device)
initialize_residual_block_weights(weights, 'layer1', 1, 64, 64, False, device)
# Layer2 (first block: 64->128, stride=2, shortcut; second: 128->128, stride=1, no shortcut)
initialize_residual_block_weights(weights, 'layer2', 0, 64, 128, True, device)
initialize_residual_block_weights(weights, 'layer2', 1, 128, 128, False, device)
# Layer3 (first block: 128->256, stride=2, shortcut; second: 256->256, stride=1)
initialize_residual_block_weights(weights, 'layer3', 0, 128, 256, True, device)
initialize_residual_block_weights(weights, 'layer3', 1, 256, 256, False, device)
# Layer4 (first block: 256->512, stride=2, shortcut; second: 512->512, stride=1)
initialize_residual_block_weights(weights, 'layer4', 0, 256, 512, True, device)
initialize_residual_block_weights(weights, 'layer4', 1, 512, 512, False, device)
# Fully connected layer
fc_w, fc_b = create_linear_param(512, 10, device=device)
weights['fc_w'], weights['fc_b'] = fc_w, fc_b
return weights
def train(weights, optimizer, train_data, train_labels, batch_size, device, mean, std):
weights = {k: v for k, v in weights.items()} # ensure we work on the dict
num_samples = len(train_labels)
indices = list(range(num_samples))
random.shuffle(indices)
total_loss = 0.0
total_correct = 0
total_batches = 0
for i in range(0, num_samples, batch_size):
batch_indices = indices[i:i+batch_size]
batch_images = train_data[batch_indices] # raw uint8 images, shape (B, C, H, W)
batch_labels = train_labels[batch_indices]
# 正则化
preprocessed = []
for img in batch_images:
# img is a uint8 tensor on device, shape (C, H, W)
img = train_preprocess(img, mean, std) # uses random crop & flip
preprocessed.append(img)
batch_x = torch.stack(preprocessed, dim=0).to(device)
logits = resnet18(batch_x, weights, is_training=True)
loss = torch.nn.functional.cross_entropy(logits, batch_labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * len(batch_indices)
total_correct += (torch.argmax(logits, dim=1) == batch_labels).sum().item()
total_batches += 1
avg_loss = total_loss / num_samples
accuracy = total_correct / num_samples * 100.0
return avg_loss, accuracy
def test(weights, test_data, test_labels, batch_size, device, mean, std):
weights = {k: v for k, v in weights.items()}
num_samples = len(test_labels)
total_correct = 0
for i in range(0, num_samples, batch_size):
batch_images = test_data[i:i+batch_size]
batch_labels = test_labels[i:i+batch_size]
# Apply test preprocessing (only normalisation, no random transforms)
preprocessed = []
for img in batch_images:
img = test_preprocess(img, mean, std)
preprocessed.append(img)
batch_x = torch.stack(preprocessed, dim=0).to(device)
with torch.no_grad():
logits = resnet18(batch_x, weights, is_training=False)
total_correct += (torch.argmax(logits, dim=1) == batch_labels).sum().item()
accuracy = total_correct / num_samples * 100.0
return accuracy
if __name__ == '__main__':
EPOCHS = 100
BATCH_SIZE = 128
LEARNING_RATE = 0.01
TRAIN_ACC_THRESHOLD = 90.0
SGD_MOMENTUM = 0.9
WEIGHT_DECAY = 1e-4
train_set = torchvision.datasets.CIFAR10(root='./cifar10_data', train=True, download=True, transform=None)
test_set = torchvision.datasets.CIFAR10(root='./cifar10_data', train=False, download=True, transform=None)
train_data_np = train_set.data.transpose(0, 3, 1, 2)
test_data_np = test_set.data.transpose(0, 3, 1, 2)
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
print(f"Using device: {device}")
train_data = torch.tensor(train_data_np, device=device)
train_labels = torch.tensor(train_set.targets, dtype=torch.long, device=device)
test_data = torch.tensor(test_data_np, device=device)
test_labels = torch.tensor(test_set.targets, dtype=torch.long, device=device)
data = train_set.data.astype(numpy.float64) / 255.0
mean = torch.tensor(data.mean(axis=(0, 1, 2)), dtype=torch.float32).to(device)
std = torch.tensor(data.std(axis=(0, 1, 2)), dtype=torch.float32).to(device)
weights = initialize_weights(device)
trainable_params = []
# running_mean 和 running_var 不是 torch.nn.Parameter,我们要把它俩拿掉
for name, param in weights.items():
if isinstance(param, torch.nn.Parameter):
trainable_params.append(param)
optimizer = torch.optim.SGD(trainable_params, lr=LEARNING_RATE,
momentum=SGD_MOMENTUM, weight_decay=WEIGHT_DECAY)
for epoch in range(1, EPOCHS + 1):
start_time = time.time()
train_loss, train_acc = train(weights, optimizer,
train_data, train_labels,
BATCH_SIZE, device, mean, std)
epoch_time = time.time() - start_time
print(f"Epoch {epoch:2d}: TrainTime = {epoch_time:.2f}s, "
f"TrainLoss = {train_loss:.4f}, TrainAcc = {train_acc:.2f}%", end=' ')
if train_acc >= TRAIN_ACC_THRESHOLD:
test_acc = test(weights, test_data, test_labels,
BATCH_SIZE, device, mean, std)
print(f"TestAcc = {test_acc:.2f}%")
else:
print()
不算下载数据集的时间,我在 1 张 Tesla T4 的显卡上训练了约 4 小时,得到了以下结果。
...
Epoch 91: TrainTime = 118.81s, TrainLoss = 0.0163, TrainAcc = 99.48% TestAcc = 91.49%
Epoch 92: TrainTime = 118.80s, TrainLoss = 0.0142, TrainAcc = 99.53% TestAcc = 91.41%
Epoch 93: TrainTime = 118.79s, TrainLoss = 0.0221, TrainAcc = 99.23% TestAcc = 91.08%
Epoch 94: TrainTime = 118.81s, TrainLoss = 0.0158, TrainAcc = 99.51% TestAcc = 91.09%
Epoch 95: TrainTime = 118.78s, TrainLoss = 0.0212, TrainAcc = 99.26% TestAcc = 90.95%
Epoch 96: TrainTime = 118.81s, TrainLoss = 0.0204, TrainAcc = 99.31% TestAcc = 90.51%
Epoch 97: TrainTime = 118.79s, TrainLoss = 0.0178, TrainAcc = 99.42% TestAcc = 91.23%
Epoch 98: TrainTime = 118.82s, TrainLoss = 0.0185, TrainAcc = 99.39% TestAcc = 91.39%
Epoch 99: TrainTime = 118.82s, TrainLoss = 0.0195, TrainAcc = 99.32% TestAcc = 91.10%
Epoch 100: TrainTime = 118.78s, TrainLoss = 0.0202, TrainAcc = 99.34% TestAcc = 91.34%
可以看到,经过 100 轮训练,测试集的准确率最终来到了 91.34%。对比 ResNet 论文 4.2 小节中披露的准确率 91.25% ,我们可以算是初步完成了 2015 年的那个 ResNet 的复现工作。和何教授一起,半只脚踏入了「深度」的世界。
4.4 PyTorch 魔法¶
小结一下,包括残差连接在内,我们走向深度其实使用了相当多的技巧。有正则、池化、批归一化、1x1 卷积、何氏初始化,以及最重要的残差连接。接下来,开始我们 PytTorch 魔法的环节,将这些我们手动实现的模块全替换成 PyTorch 的高级 API,以供我们未来更快更稳的搭建更强的网络。
回忆一下我们的魔法袋已经有了的 Torch 卷轴们,昨天我们总结过的。
| 网络层 | 损失函数 | 优化器 | 其它 |
|---|---|---|---|
nn.Flatten() 展平层 |
nn.MSELoss() 均方误差损失 |
torch.optim.SGD 随机梯度下降 |
data.to('cuda') 数据移至 GPU |
nn.Linear() 线性层 / 全连接层 |
nn.CrossEntropyLoss() 交叉熵损失 |
load_dataset() 数据加载器 |
|
nn.ReLU() ReLU 激活函数 |
|||
nn.Sequential() 层连接器 |
想想看,今天除了 nn.MSELoss(),其它的我们应该都能用上。
还能新添一些到我们的魔法口袋。
4.4.1 Torch 内置卷积层¶
我们手工实现的卷积层 manual_conv2d() 是有 PyTorch 版本的。并且参数相当丰富。
self.conv1 = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False)
4.4.2 Torch 内置批归一化层¶
我们手工实现的批归一化层 manual_batch_norm() 是有 PyTorch 版本的。
4.4.3 Torch 内置池化层¶
我们手工实现的平均池化层 manual_avg_pool2d() ,也是有 PyTorch 版本的。
这些能叫得出名字的网络层,在 Torch 中多半都有内置实现。这一点想必大家都不意外。
那么,既然这些常规的项目我们已经有点倦怠了。下面我们来整两个大活。
4.4.4 nn.Module¶
之前我们手动实现的版本和 PyTorch 版本的主要的区别在于优化的力度不足。它的版本常常在资源利用上更细,也更舍得深入使用 GPU 指令和预计算的常数去优化代码。
但 PyTorch 端上桌的肯定是不止这些力工活。它还提供了像 nn.Module 这样的招式,引导我们去弥补工程上的不足。
观察我们实现的残差模块,主要网络定义在 residual_block() 函数,参数初始化在 initialize_residual_block_weights() 函数,最后我们还得用 for name, param in weights.items() 过滤所有可学习的权重喂给 optimizer 去梯度下降。
作为代码的读者,想要理解我们的残差模块,要读 3 个地方的代码才能了然。我们把它这样拆分成 3 块是合适的吗?
不好说。
虽然大家都嘴上说着写软件要高内聚低耦合。但是前几年打开大模块的内部,号称基于 FaaS 就可以放任服务遍地的 Netflix 微服务架构一时也风头无两。像养育一个孩子,大家都知道,要爱但不要溺爱,要教育但不要控制。但用嘴总是容易些,爱和溺爱之间,勇武和鲁莽之间,边界在哪里呢?这才是真正的难题。我相信,经过了一定数量项目的程序员,开发了一些产品的组织,都会在劳动和协作实践中思考,形成自己对这个边界的偏好。

图 4-14 Netflix Senior Engineer Dave Hahn proudly showing off the Netflix microservices architecture
对于还处在起步阶段的你我,直取成熟的取舍会是一个不错的开始。PyTorch 用 nn.Module 给出了它的偏好 —— 这三个逻辑放一起好些。
并且,PyTorch 提供给我们的 nn.Module 这个抽象类,让我们可以非常方便地基于它的这个理解拼插出一个神经网络。省略了一些钩子函数,它的定义大概长这样。
class torch.nn.Module(*args, **kwargs):
def __init__(self, *args, **kwargs):
def forward(self, *input):
def add_module(self, name, module):
def apply(self, fn):
def children(self):
def compile(self, *args, **kwargs):
def cpu(self):
def cuda(self, device=None):
def eval(self):
def get_buffer(self, target):
def get_extra_state(self):
def get_parameter(self, target):
def get_submodule(self, target):
def load_state_dict(self, state_dict, strict=True, assign=False):
def modules(self, remove_duplicate=True):
def parameters(self, recurse=True):
def requires_grad_(self, requires_grad=True):
def set_extra_state(self, state):
def set_submodule(self, target, module, strict=False):
def share_memory(self):
def state_dict(self, *, destination=None, prefix='', keep_vars=False):
def to(self, *args, **kwargs):
def to_empty(self, *, device, recurse=True):
def train(self, mode=True):
def xpu(self, device=None):
def zero_grad(self, set_to_none=True):
可以看到, nn.Module 集合了一个网络周遭的几乎一切,包括 train 训练、eval 测试、add_module 加子网络、forward 前向推理等。
4.4.4.1 forward() 前向推理¶
其中最重要的的方法是 forward() 前向推理。这是我们一个必须实现的方法。Pytorch 使用了通过 python 的 __call__ 使得我们在调用 网络名() 的时候,实际上调用的就是这个 forward() 方法。举个例子。
import torch.nn as nn
class MyModel(nn.Module):
def __init__(self) -> None:
super().__init__()
self.relu = nn.ReLU()
def forward(self, x):
out = self.relu(x)
return out
比如说,如果我们像上面这样用 nn.Module 实现了一个网络。那么,当我们调用 MyModel(input) 时,实际就会调用到 MyModel.forward(input) 方法。这个例子也是最简单的 nn.Module 的用法。
用这种方法,我们可以三合一的把我们的残差模块改写成下面这样。
class ResidualBlock(torch.nn.Module):
def __init__(self, in_channels, out_channels, stride=1, use_shortcut=False):
super().__init__()
self.conv1 = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = torch.nn.BatchNorm2d(out_channels)
self.conv2 = torch.nn.Conv2d(out_channels, out_channels, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = torch.nn.BatchNorm2d(out_channels)
self.relu = torch.nn.ReLU(inplace=True)
self.shortcut = torch.nn.Sequential()
if use_shortcut:
self.shortcut = torch.nn.Sequential(
torch.nn.Conv2d(in_channels, out_channels, kernel_size=1,
stride=stride, padding=0, bias=False),
torch.nn.BatchNorm2d(out_channels)
)
def forward(self, x):
identity = x
if self.shortcut:
identity = self.shortcut(x)
out = self.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += identity
out = self.relu(out)
return out
代码很平铺直叙。但我们注意到,我们的实现中没有参数初始化方法。因为,ResidualBlock 作为 ResNet-18 的子网络,我们打算在 ResNet-18 的实现中一并初始化包括 ResidualBlock 在内的所有参数。
4.4.4.2 apply() 对每个子网络执行函数¶
我们用 apply() 做初始化。我们传一个函数给它,它会对每个子网络执行一次这个函数。用做参数初始化正合适。
然后我们的 ResNet-18 就可以改写成这样。
class ResNet18(torch.nn.Module):
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = torch.nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = torch.nn.BatchNorm2d(64)
self.relu = torch.nn.ReLU(inplace=True)
self.layer1 = torch.nn.Sequential(
ResidualBlock(64, 64, stride=1, use_shortcut=False),
ResidualBlock(64, 64, stride=1, use_shortcut=False)
)
self.layer2 = torch.nn.Sequential(
ResidualBlock(64, 128, stride=2, use_shortcut=True),
ResidualBlock(128, 128, stride=1, use_shortcut=False)
)
self.layer3 = torch.nn.Sequential(
ResidualBlock(128, 256, stride=2, use_shortcut=True),
ResidualBlock(256, 256, stride=1, use_shortcut=False)
)
self.layer4 = torch.nn.Sequential(
ResidualBlock(256, 512, stride=2, use_shortcut=True),
ResidualBlock(512, 512, stride=1, use_shortcut=False)
)
self.avgpool = torch.nn.AvgPool2d(kernel_size=4)
self.flatten = torch.nn.Flatten()
self.fc = torch.nn.Linear(512, 10)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, torch.nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, torch.nn.Linear):
torch.nn.init.kaiming_uniform_(m.weight, a=5 ** 0.5)
if m.bias is not None:
torch.nn.init.constant_(m.bias, 0)
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = self.flatten(out)
out = self.fc(out)
return out
网络的形状和我们手动实现的是一模一样的,但更加一目了然了。我们自己定义了 _init_weights() 方法,并且在 __init__() 类初始化的末尾利用 apply() 方法对每个子网络执行了一遍。在 _init_weights() 方法中,我们判断了传进来的子网络的类型,执行了对应的参数初始化。
4.4.4.3 parameters() 获取所有参数¶
nn.Module 的 parameters() 会返回一个包含网络中所有 torch.nn.Parameter 实例的迭代器。利用这个接口,我们可以不经大脑地,准确地一口气把网络中的所有参数全部传给优化器。
这样,当我们调用 loss.backward() 求导时,PyTorch 就会自动将梯度加到这些实例的 .grad 属性中。而后我们调用 optimizer.step() 时,优化器就帮我们自动更新所有参数了。
所以,用了 nn.Module,这一切我们就撒手了,交给 PyTorch 去完成。
值得注意的是,如果我们自己在 __init__() 中不是用的基于 nn.Module 创建的子类,那我们还是需要自己把自己写的变量用nn.Parameter() 包起来。这样它才会被注册到父 nn.Module 中,后续参与前所述的自动化过程。类似下面这样。
import torch
import torch.nn as nn
class MyModuleWithParameter(nn.Module):
def __init__(self):
super().__init__()
# 可学习参数
self.w1 = nn.Parameter(torch.randn(2))
# 不可学习参数
self.w2 = torch.tensor([1.0, 1.0])
def forward(self, x):
return self.w1 + self.w2
4.4.4.4 train() 切换训练模式¶
对于归一化操作而言,mean 和 std 在训练时是要统计的,但是在推理时是不计算的,是直接用的训练时统计出的值。
手动版本中,我们在 manual_batch_norm() 函数,通过 training 参数来控制我们的批归一化层是处于训练模式还是推理模式。
用了 nn.Module,它的 train() 方法会帮我们将包括批归一化层在内的所有类似这样性质的子网络切换到训练模式。
所以,我们需要在我们的训练方法的第一行就调用这个函数。
def train(model, optimizer, train_loader, device):
model.train()
total_loss = 0.0
total_correct = 0
num_samples = 0
for batch_x, batch_y in train_loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
logits = model(batch_x)
loss = torch.nn.functional.cross_entropy(logits, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * batch_x.size(0)
total_correct += (logits.argmax(dim=1) == batch_y).sum().item()
num_samples += batch_x.size(0)
avg_loss = total_loss / num_samples
accuracy = total_correct / num_samples * 100.0
return avg_loss, accuracy
4.4.4.5 eval() 切换推理模式¶
同理的,nn.Module 的 eval() 方法帮我们用于将所有子网络切换到推理模式。
我们在推理函数的第一行调用它。其它逻辑和我们的手动版本保持一致。
def test(model, test_loader, device):
model.eval()
total_correct = 0
num_samples = 0
with torch.no_grad():
for batch_x, batch_y in test_loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
logits = model(batch_x)
total_correct += (logits.argmax(dim=1) == batch_y).sum().item()
num_samples += batch_x.size(0)
accuracy = total_correct / num_samples * 100.0
return accuracy
你觉得怎么样?我觉得在 nn.Module 的帮助下,网络的可读性大幅增强,对我大脑「脑存」的占用大幅减少了。
在我们这个阶段,自定义网络时从 nn.Module 继承是个相当不错的选择。PyTorch 自己也经常使用这个抽象类,之前我们用的 nn.Linear 和 nn.ReLU 也都是 nn.Module 的子类。
网络 OK 了。下一步,把数据加载进来训练就完事了。
4.4.5 DataLoader¶
回顾一下我们手动版本是如何实现分批次加载数据的。
def train(weights, optimizer, train_data, train_labels, batch_size, device, mean, std):
# ...
for i in range(0, num_samples, batch_size):
batch_indices = indices[i:i+batch_size]
batch_images = train_data[batch_indices]
batch_labels = train_labels[batch_indices]
# ...
就 3 行,简洁完美地实现了分批次训练的需求。给自己点个赞。
但是,如果我们面对数据集不是 CIFAR-10 这种几百兆的小家伙,而是 ImageNet 那样上太的大块头呢?还完美吗?
那么,这个实现就得多考虑 2 个问题。
-
虽然我们用 for 分批次把数据喂给 GPU 去算,但是在我们
train()的train_data参数中,所有的数据已经加载到显存中在等着了。对于 CIFAR-10 来说,没问题。要是有一天 ImageNet-21K 来了,1.31 个太,显存装不下。怎么办? -
在把数据送进 GPU 之前,我们对数据做了归一化处理。这个归一化处理也是用 for 去完成的,意味着是串行完成的。如果我们在机器上有很多颗性能很好的 CPU,这个工作能不能让 CPU 并行完成?
# ...
# 正则化
preprocessed = []
for img in batch_images:
# img is a uint8 tensor on device, shape (C, H, W)
img = train_preprocess(img, mean, std) # uses random crop & flip
preprocessed.append(img)
batch_x = torch.stack(preprocessed, dim=0).to(device)
logits = resnet18(batch_x, weights, is_training=True)
# ...
动动嘴皮子倒也不难。
-
按需加载。不要一次性把所有数据读进来。每次只读当前批次需要的数据喂给 GPU;
-
开多线程异步处理。
spawn、join、async、await搞定它。
答案虽然简单,两个短句就说完了。但这两个短句一个是分页问题、另一个是多线程异步。这两个问题看似不搭噶,但其实隐藏有一个共同点 —— 都适合刚学编程的新手或是搞了编程三十年的老油条去搞。不巧的是,我正处于一个尴尬的、既了解它们不敢直面它们的中登地带。
幸而有 torch.utils.data.DataLoader 。
它把上面两件事都给承包了。我们只要把我们的数据集转成 DataLoader 迭代器,告诉它我们想要的分页大小和并发线程数。
train_set = torchvision.datasets.CIFAR10(root='./cifar10_data', train=True, download=True)
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=BATCH_SIZE,
shuffle=True, num_workers=0) # num_workers=0 意思是不用多线程,n 指开 n 个线程
然后,我们就能完全无痛地、简单地享受它的劳动成果了。
def train(model, optimizer, train_loader, device):
# ...
for batch_x, batch_y in train_loader:
# ...
# ...
这样我们就可以无痛无责地同时享受分页和多线程了。要是多线程没整对,一封邮件直接甩锅给它,接得又准又稳。
4.4.6 torchvision.transforms¶
两个大活整完了。网络也 OK 了,数据也加载进来了。最后咱来个餐后小甜点。
我们预处理数据的正则化过程,用 PyTorch 也可以更便捷地完成。回顾一下我们之前做的预处理。
def train_preprocess(img_tensor, mean, std):
# 四边都加上 4 个像素的黑边,将我们的 32x32 的图像变成 40x40
img = torchvision.transforms.functional.pad(img_tensor, padding=4, fill=0)
# 随机裁剪回 32x32
top = random.randint(0, 8)
left = random.randint(0, 8)
img = torchvision.transforms.functional.crop(img, top, left, 32, 32)
# 将一半的图像水平翻转
if random.random() < 0.5:
img = torchvision.transforms.functional.hflip(img)
# 归一化(标准化)
img = img.float() / 255.0
img = (img - mean.view(3, 1, 1)) / std.view(3, 1, 1)
return img
PyTorch 可以在加载数据集的同时就完成预处理。
train_transform = torchvision.transforms.Compose([
torchvision.transforms.RandomCrop(32, padding=4),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean, std)
])
上面代码中的 padding=4 等价于我们第一步的加黑边,RandomCrop(32) 等价我们第二步的随机裁剪,RandomHorizontalFlip() 等价我们第三步的随机水平翻转。
这三步都是针对图像的操作,最后一步归一化 Normalize(mean, std) 是针对张量的操作。所以,插入一个 ToTensor() 转张量。
然后,用 torchvision.transforms.Compose 攒一堆,加载数据集的时候传进去,得到的就直接是归一化后的数据集了。
train_set = torchvision.datasets.CIFAR10(
root='./cifar10_data', train=True,
download=True, transform=train_transform)
4.4.7 全部收拢¶
有了以上的高级魔法,我们就可以把我们的程序进化成这个样子。
import torch
import torchvision
import torchvision.transforms
import numpy
import time
import random
class ResidualBlock(torch.nn.Module):
def __init__(self, in_channels, out_channels, stride=1, use_shortcut=False):
super(ResidualBlock, self).__init__()
self.conv1 = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = torch.nn.BatchNorm2d(out_channels)
self.conv2 = torch.nn.Conv2d(out_channels, out_channels, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = torch.nn.BatchNorm2d(out_channels)
self.relu = torch.nn.ReLU(inplace=True)
self.shortcut = torch.nn.Sequential()
if use_shortcut:
self.shortcut = torch.nn.Sequential(
torch.nn.Conv2d(in_channels, out_channels, kernel_size=1,
stride=stride, padding=0, bias=False),
torch.nn.BatchNorm2d(out_channels)
)
def forward(self, x):
identity = x
if self.shortcut:
identity = self.shortcut(x)
out = self.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += identity
out = self.relu(out)
return out
class ResNet18(torch.nn.Module):
def __init__(self):
super(ResNet18, self).__init__()
self.conv1 = torch.nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = torch.nn.BatchNorm2d(64)
self.relu = torch.nn.ReLU(inplace=True)
self.layer1 = torch.nn.Sequential(
ResidualBlock(64, 64, stride=1, use_shortcut=False),
ResidualBlock(64, 64, stride=1, use_shortcut=False)
)
self.layer2 = torch.nn.Sequential(
ResidualBlock(64, 128, stride=2, use_shortcut=True),
ResidualBlock(128, 128, stride=1, use_shortcut=False)
)
self.layer3 = torch.nn.Sequential(
ResidualBlock(128, 256, stride=2, use_shortcut=True),
ResidualBlock(256, 256, stride=1, use_shortcut=False)
)
self.layer4 = torch.nn.Sequential(
ResidualBlock(256, 512, stride=2, use_shortcut=True),
ResidualBlock(512, 512, stride=1, use_shortcut=False)
)
self.avgpool = torch.nn.AvgPool2d(kernel_size=4)
self.flatten = torch.nn.Flatten()
self.fc = torch.nn.Linear(512, 10)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, torch.nn.Conv2d):
torch.nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, torch.nn.Linear):
torch.nn.init.kaiming_uniform_(m.weight, a=5 ** 0.5)
if m.bias is not None:
torch.nn.init.constant_(m.bias, 0)
def forward(self, x):
out = self.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = self.flatten(out)
out = self.fc(out)
return out
def train(model, optimizer, train_loader, device):
model.train()
total_loss = 0.0
total_correct = 0
num_samples = 0
for batch_x, batch_y in train_loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
logits = model(batch_x)
loss = torch.nn.functional.cross_entropy(logits, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * batch_x.size(0)
total_correct += (logits.argmax(dim=1) == batch_y).sum().item()
num_samples += batch_x.size(0)
avg_loss = total_loss / num_samples
accuracy = total_correct / num_samples * 100.0
return avg_loss, accuracy
def test(model, test_loader, device):
model.eval()
total_correct = 0
num_samples = 0
with torch.no_grad():
for batch_x, batch_y in test_loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
logits = model(batch_x)
total_correct += (logits.argmax(dim=1) == batch_y).sum().item()
num_samples += batch_x.size(0)
accuracy = total_correct / num_samples * 100.0
return accuracy
if __name__ == '__main__':
EPOCHS = 100
BATCH_SIZE = 128
TRAIN_ACC_THRESHOLD = 90.0
# 首次加载数据集,目的是计算均值和标准差
temp_train_set = torchvision.datasets.CIFAR10(root='./cifar10_data', train=True, download=True, transform=None)
data_np = temp_train_set.data.astype(numpy.float64) / 255.0
mean = torch.tensor(data_np.mean(axis=(0, 1, 2)), dtype=torch.float32)
std = torch.tensor(data_np.std(axis=(0, 1, 2)), dtype=torch.float32)
# 定义我们的正则化 transform
train_transform = torchvision.transforms.Compose([
torchvision.transforms.RandomCrop(32, padding=4),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean, std)
])
test_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean, std)
])
# 再次加载数据集,应用我们的正则化
train_set = torchvision.datasets.CIFAR10(root='./cifar10_data', train=True, download=True, transform=train_transform)
test_set = torchvision.datasets.CIFAR10(root='./cifar10_data', train=False, download=True, transform=test_transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True, num_workers=0)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=BATCH_SIZE, shuffle=False, num_workers=0)
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
print(f"Using device: {device}")
model = ResNet18().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=1e-4)
for epoch in range(1, EPOCHS + 1):
start_time = time.time()
train_loss, train_acc = train(model, optimizer, train_loader, device)
epoch_time = time.time() - start_time
print(f"Epoch {epoch:2d}: TrainTime = {epoch_time:.2f}s, "
f"TrainLoss = {train_loss:.4f}, TrainAcc = {train_acc:.2f}%", end=' ')
if train_acc >= TRAIN_ACC_THRESHOLD:
test_acc = test(model, test_loader, device)
print(f"TestAcc = {test_acc:.2f}%")
else:
print()
这段代码在我的 Tesla T4 运行了大概 2 个小时,得到了以下结果。
...
Epoch 91: TrainTime = 52.12s, TrainLoss = 0.0216, TrainAcc = 99.23% TestAcc = 90.96%
Epoch 92: TrainTime = 51.73s, TrainLoss = 0.0205, TrainAcc = 99.30% TestAcc = 91.28%
Epoch 93: TrainTime = 51.79s, TrainLoss = 0.0218, TrainAcc = 99.24% TestAcc = 91.59%
Epoch 94: TrainTime = 51.74s, TrainLoss = 0.0171, TrainAcc = 99.42% TestAcc = 91.12%
Epoch 95: TrainTime = 51.75s, TrainLoss = 0.0129, TrainAcc = 99.60% TestAcc = 91.77%
Epoch 96: TrainTime = 51.78s, TrainLoss = 0.0173, TrainAcc = 99.38% TestAcc = 91.75%
Epoch 97: TrainTime = 51.88s, TrainLoss = 0.0157, TrainAcc = 99.48% TestAcc = 91.64%
Epoch 98: TrainTime = 52.12s, TrainLoss = 0.0175, TrainAcc = 99.41% TestAcc = 91.33%
Epoch 99: TrainTime = 51.88s, TrainLoss = 0.0213, TrainAcc = 99.27% TestAcc = 91.51%
Epoch 100: TrainTime = 51.82s, TrainLoss = 0.0232, TrainAcc = 99.16% TestAcc = 90.98%
果然 PyTorch 实现的版本,跟我们手动实现的相比,又快又好!而且吃掉的显存也从 6G 缩到了 2G 多一点。虽然每个网络层的实现中,PyTorch 肯定都比我们更精细化地即时释放显存,但我想,主要节省显存的功劳还是应该归功于 DataLoader 的分批加载。吃多少盛多少,少量多次,不浪费。幸好我们先拿 CIFAR-10 试了试水,要是一上来就整 ImageNet,显存得炸。
这样,我们用更高级的 Torch API 又实现了一版 ResNet-18。
但其实,PyTorch 还没火力全开。
4.4.8 究极奥义¶
PyTorch 直接内置了 ResNet-18 的完整实现。
我们可以不用来回拼插试错,直接得到一个绝对正确的 ResNet-18。
就像网络上那个哏 —— 想要什么?直接成为。
import torch
import torch.nn
import torch.optim
import torchvision
import torchvision.transforms
import time
# 正则化
transform_train = torchvision.transforms.Compose([
torchvision.transforms.RandomCrop(32, padding=4),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
transform_test = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 读数据集
train_set = torchvision.datasets.CIFAR10(root='./cifar10_data', train=True, download=True, transform=transform_train)
test_set = torchvision.datasets.CIFAR10(root='./cifar10_data', train=False, download=True, transform=transform_test)
# DataLoader 加载数据集
train_loader = torch.utils.data.DataLoader(train_set, batch_size=128, shuffle=True, num_workers=2)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=128, shuffle=False, num_workers=2)
# 侦测 GPU 类型
if torch.cuda.is_available():
device = torch.device("cuda")
elif torch.backends.mps.is_available():
device = torch.device("mps")
else:
device = torch.device("cpu")
print(f"Using device: {device}")
# 一句话得到 ResNet-18
model = torchvision.models.resnet18(weights=None, num_classes=10)
model = model.to(device)
# 选择损失函数
criterion = torch.nn.CrossEntropyLoss()
# 选择优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=1e-4)
# 开始训练
for epoch in range(1, 101):
start_time = time.time()
model.train()
train_loss = 0.0
train_correct = 0
train_total = 0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
_, predicted = outputs.max(1)
train_total += labels.size(0)
train_correct += predicted.eq(labels).sum().item()
epoch_time = time.time() - start_time
train_loss = train_loss / train_total
train_acc = 100.0 * train_correct / train_total
print(f"Epoch {epoch:2d}: TrainTime = {epoch_time:5.2f}s, "
f"TrainLoss = {train_loss:.4f}, TrainAcc = {train_acc:.2f}%", end=' ')
# 如果在训练集上的准确率达到 90%,那么就开始试试测试集的准确率
if train_acc >= 90.0:
model.eval()
test_correct = 0
test_total = 0
with torch.no_grad():
for inputs, labels in test_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = outputs.max(1)
test_total += labels.size(0)
test_correct += predicted.eq(labels).sum().item()
test_acc = 100.0 * test_correct / test_total
print(f"TestAcc = {test_acc:.2f}%")
else:
print()
PyTorch 内置的 ResNet-18 是为训练 ImageNet 那样的大图而设计的。我们往回翻一翻,参见图 4-5,它一上来就整了一个7x7 的大卷积核,并且跟着又来了一个最大池化。这对我们 32x32 本来像素就很少的图像来说,都是很不利的。所以,同样的 100 轮学习,它的准确率只来到了83.35%。
但快是真的快,这 100 轮在我的 Tesla T4 上只用了 18 分钟,很强大的优化!
...
Epoch 91: TrainTime = 9.96s, TrainLoss = 0.1395, TrainAcc = 95.03% TestAcc = 83.08%
Epoch 92: TrainTime = 9.51s, TrainLoss = 0.1420, TrainAcc = 94.98% TestAcc = 82.66%
Epoch 93: TrainTime = 9.84s, TrainLoss = 0.1412, TrainAcc = 94.94% TestAcc = 82.77%
Epoch 94: TrainTime = 12.30s, TrainLoss = 0.1387, TrainAcc = 95.05% TestAcc = 83.11%
Epoch 95: TrainTime = 10.70s, TrainLoss = 0.1297, TrainAcc = 95.35% TestAcc = 82.96%
Epoch 96: TrainTime = 11.62s, TrainLoss = 0.1374, TrainAcc = 95.10% TestAcc = 83.04%
Epoch 97: TrainTime = 9.62s, TrainLoss = 0.1341, TrainAcc = 95.19% TestAcc = 82.98%
Epoch 98: TrainTime = 9.61s, TrainLoss = 0.1286, TrainAcc = 95.37% TestAcc = 83.37%
Epoch 99: TrainTime = 9.87s, TrainLoss = 0.1288, TrainAcc = 95.48% TestAcc = 83.48%
Epoch 100: TrainTime = 9.43s, TrainLoss = 0.1248, TrainAcc = 95.52% TestAcc = 83.35%
训练过程中,它的资源占用是这样的。
(base) root@VM-0-80-ubuntu:/workspace/cifar10# nvidia-smi
Sun Apr 5 22:54:43 2026
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:09.0 Off | 0 |
| N/A 64C P0 72W / 70W | 1308MiB / 15360MiB | 59% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
可以观察到,经过 PyTorch 的优化,网络训练的速度提升了近 10 倍,显存用量从近 6G 缩到了不到 2G。这里主要的优化,我猜想除了上个版本的 DataLoader,它应该是不嫌麻烦地使用了混合精度训练。
但这引发了一个新问题 —— 我这 16G 显存的 Tesla T4 剩下的那 14G 咋办?大哥打架,你们就站着看?并且, GPU 使用率也没有跑满。真就一核有难,八核围观是吧……
4.4.9 未竟事宜¶
4.4.9.1 超参数调整¶
想要装满显存,一个很自然的想法就是调大 BATCH_SIZE,一次喂进去更多数据,显存不就用得更多了。
模型里的那些权重浮点值也可以被称为参数,那么像 BATCH_SIZE 这样影响模型参数的参数,很多人都管它们叫「超参数」Hyperparameter。就像数据的数据被称为「元数据」Metadata 一样。
调高 BATCH_SIZE 应该是能吃掉更多显存。我们把 BATCH_SIZE 改成 512,别的不动,跑跑看。
(base) root@VM-0-80-ubuntu:/workspace# nvidia-smi
Wed Apr 8 17:51:34 2026
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.105.17 Driver Version: 525.105.17 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:00:09.0 Off | 0 |
| N/A 70C P0 63W / 70W | 14542MiB / 15360MiB | 100% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
这下显存确实吃光了,GPU 也跑到了 100%。得到了以下结果。
...
Epoch 91: TrainTime = 116.83s, TrainLoss = 0.0268, TrainAcc = 99.08% TestAcc = 87.54%
Epoch 92: TrainTime = 117.01s, TrainLoss = 0.0250, TrainAcc = 99.21% TestAcc = 87.53%
Epoch 93: TrainTime = 116.99s, TrainLoss = 0.0265, TrainAcc = 99.12% TestAcc = 86.82%
Epoch 94: TrainTime = 117.02s, TrainLoss = 0.0286, TrainAcc = 99.06% TestAcc = 87.76%
Epoch 95: TrainTime = 117.13s, TrainLoss = 0.0267, TrainAcc = 99.10% TestAcc = 87.60%
Epoch 96: TrainTime = 116.89s, TrainLoss = 0.0280, TrainAcc = 99.07% TestAcc = 86.74%
Epoch 97: TrainTime = 116.93s, TrainLoss = 0.0299, TrainAcc = 98.97% TestAcc = 88.19%
Epoch 98: TrainTime = 116.95s, TrainLoss = 0.0244, TrainAcc = 99.18% TestAcc = 87.78%
Epoch 99: TrainTime = 116.98s, TrainLoss = 0.0216, TrainAcc = 99.33% TestAcc = 87.95%
Epoch 100: TrainTime = 117.11s, TrainLoss = 0.0233, TrainAcc = 99.25% TestAcc = 87.79%
用了更多显存,准确率反倒不如之前了?
想想看,之前我们把全部数据训练改为分批量训练,是为了一定程度上的「正则化」。那现在我们加大每批次的大小,是不是其实就往「反正则化」在走呢?如果我们做了「反正则化」的事,那训练出来的模型就会更加不容易泛化,或者说更加倾向于记住训练集了。要是这个逻辑没问题,那么,它在测试集的表现下降就好理解了。
那我们怎么办呢?我看到网上好多玩神经网络的同学自嘲为调参侠,调参侠们面对这种情况时会怎么办呢?
4.4.9.2 Attention Residuals¶
更深的网络拥有更强的表达力,能将更为复杂的规律蕴藏其中,这是毫无疑问的。
一度大家都没有好的工具,也没想到好的办法去训练它。进入 GPU 时代后,我们以残差连接为核心,在围绕它身边的正则、参数初始化、池化、归一化等诸多创新的共同努力下,终于具备了训练一个「深度神经网络」的能力。
我们可以把深度神经网络想象成一个二维的矩阵。它的列是我们 Flatten 之后的一系列的输入数据的特征,行是一层层的神经网络层。

图 4-15 设想深度神经网络是一个矩阵
如果这样想象的话,那么深度神经网络训练的过程,就是输入数据一遍又一遍地从最上面一行下降到最下面一行,然后又返回第一行的过程。
前 4 天,前辈们的努力使得这个矩阵可以容纳很多的层,即在纵向上充分拉长。
但故事没有终结,还有 2 个问题亟待回答。
-
是能训练很多层了,但效率呢?会不会像破解 RSA 密码那样 —— 确定能破,但是请等 1000 年吧。当层数真的无限扩展,训练效率是不是能接受呢?
-
纵向上能扩展了,那么横向呢?目前我们面对是图像输入,32x32,很小。即使是更高分辨率的图像,我们也能通过池化的方法将其迅速缩小到一个可接受的范围。但是如果问题来到文字领域呢?如果我们收到一段足够长的文字,我们能处理它吗?如果不能有效处理,我们有方法有效地缩小它到可处理的范围吗?
4 年前,ChatGPT 爆发了,意味着这两个问题应该是都得到了一定程度的回答。
在横向上的那个问题,目前的最佳答案是大名鼎鼎的注意力机制,它能帮助我们在横向上,即面对一个长的特征序列时能更加有效率地抽取其中最重要的信息进行「池化」处理,并且是并行地处理。
总结一下。残差连接使得纵向可以扩展,遗留了效率问题。注意力机制使得横向足够有效,遗留了横向的扩展问题。
2026 年 3 月 16 日,在 Kimi 工作的高中生陈广宇、旋转位置编码提出者苏剑林、Kimi Linear的作者张宇作为共同一作发表了一篇论文名为《Attention Residuals》 注意力残差。文中第 3 节他们提出,他们在这个矩阵的横向和纵向维度上观察到了对偶性,即横向和纵向本质上可能是类似的问题。旋即,它们把原作用于横向上解决效率问题的注意力机制作用于纵向上,将纵向上网络训练的效率提升了 25%。
既然是对偶,那其实很难不去幻想,如果把残差连接的思路应用到横向上会发生什么呢?能不能缓解 2026 年仍然阻塞大模型进展,逼得大家整出无数花活的上下文长度问题呢?
幻想收一收先,那么难的问题留给大神们去思考。我们还是收拾一下我们的 PyTorch 魔法小行囊,看看今天,我们又捡拾了些什么进来。
| 网络层 | 损失函数 | 优化器 | 其它 |
|---|---|---|---|
nn.Flatten() 展平层 |
nn.MSELoss() 均方误差损失 |
torch.optim.SGD() 随机梯度下降 |
data.to('cuda') 数据移至 GPU |
nn.Linear() 线性层 / 全连接层 |
nn.CrossEntropyLoss() 交叉熵损失 |
load_dataset() 数据加载器 |
|
nn.ReLU() ReLU 激活函数 |
DataLoader 数据分批次使用 |
||
nn.Sequential() 层连接器 |
torchvision.transforms 数据预处理 / 正则化 |
||
nn.Conv2d() 卷积层 |
nn.init.* 参数初始化 |
||
nn.BatchNorm2d() 批归一化层 |
|||
nn.AvgPool2d() 平均池化层 |
|||
nn.Module 自定义网络 |
深度神经网络跟前代神经网络相比,似乎并无范式上的跃进。然而,无论是因为缺了算力硬件的硬约束,还是因为缺了灵光一闪的软约束,在这两个时代间,科学家们确实停滞了好几十年。深度神经网络的最终出现,让大家终于长舒了一口气。它配得上一个崭新的名字 —— “深度学习”。
恭喜你和我。恭喜我们迈进了深度的门。或者说,我们终于吱吱呀呀的推开了这扇现代神经网络的厚重大门。迈步再往里走,经过一扇名为「Attension」的影壁,我们就将置身神经网络的正院,一览那些更为大家所熟悉的,更加激动人心的技术变革和产品创新。
我们明天见。
4.5 Small Talk:和 AI 扯扯淡¶
4.5.1 提问¶
以前说网络通信受限于光速,所以某些应用的延迟是不可被解决的问题。谁曾想乘着 5g 的东风出来一个边缘计算的概念,提供了一个新角度把这事给办了。
这让我想起曾经延续几千年的「皇权不下县」,那现在不也网格得挺好。想来这应该是通信技术进步的功劳。带宽问题解决了,下一个瓶颈就是算力了。随着 AI 的发展,人类社会的结构会不会也来一次「边缘计算」,下放一个大模型作为「决策算力」到底下或者战区等结构里做「边缘决策」啊?
这要是真发生了,是会像通信进步那样使得权力进一步集中化吗?该会如何影响人类社会结构的变化呢?是会有能力组织起更大规模更复杂的组织结构从而走向深空呢?还是会迫使个体向组织让渡更多权利?我们会因此变得更幸福还是不幸呢?
4.5.2 MiniMax-M2.7 答¶
这是一个非常有意思的思辨性问题。你把技术演进与社会治理结构联系起来的思考方式很有启发性。让我来深入分析一下这个"边缘计算"与社会"边缘决策"的类比。
4.5.2.1 技术范式与社会范式的深层映射¶
- 边缘计算的实质
边缘计算的本质并非简单地"把计算放到边缘",而是一种 分布式智能架构的重构 。传统模式是"数据向中心汇聚→中心处理→指令下传",边缘计算则实现了"近端感知→近端决策→近端执行"的闭环。这解决了两个根本矛盾:一是光速限制带来的物理延迟,二是中心节点的处理瓶颈与单点故障风险。
关键洞察在于:边缘计算并非对中心化的否定,而是 层次化计算的再组织 。中心云仍然承担着全局协调、资源调度、模型训练等核心职能,边缘节点则在时效性敏感的场景中承担实时推理和快速响应的职责。两者形成的是一种"云边协同"的新型架构。
- 社会治理结构的通信约束
回顾"皇权不下县"的历史,我们能清晰地看到通信技术的决定性影响。秦汉时期帝国能够直接管理的行政单位止于县一级,主要原因是信息传递速度的物理限制——骑马传递公文的效率决定了中央不可能对基层事务进行实时监督和精准干预。即便建立了复杂的监察制度,中央对地方的实际控制力仍然相当有限。
然而这种"边缘自主"并非现代意义上的分权,而是一种 无奈的妥协 。中央的权威是抽象的和象征性的,具体治理依赖于地方精英的自我约束和乡绅自治传统。这种模式在农业文明的慢节奏社会中尚能运转,但在面临需要快速动员和统一协调的现代事务时便显得力不从心。
- AI 赋能"边缘决策"的技术可能性
当大型语言模型能够在边缘设备上部署时,确实打开了全新的可能性空间。考虑以下场景的实现。
军事领域 :战术级AI可以在没有稳定网络连接的战区环境下,完成实时战场态势分析、威胁评估和行动建议。这类决策的时效性要求极高,中心化系统的延迟在实战中可能是致命的。边缘AI能够将决策周期从分钟级压缩到秒级,同时保持足够的决策质量。
应急响应 :自然灾害发生时,通信基础设施可能部分或完全瘫痪。部署在地方的边缘AI可以自主协调资源调配、人员疏散和救援优先级排序,无需等待中央的远程指挥。
基层治理 :社区级别的AI助手可以帮助处理日常行政事务的初步筛查和分类,将真正需要人工介入的复杂案例向上推送。这类似于边缘计算中的"数据过滤"机制。
- 潜在的社会结构变迁
权威的分散化与再集中
历史的吊诡之处在于:每次通信革命都同时包含去中心化和再中心化的力量。电报让中央能够实时掌握远方动态,强化了国家权力;互联网降低了信息传播门槛,却也在某些层面催生了新的信息垄断者。
AI驱动的边缘决策可能遵循同样的辩证逻辑。一方面,边缘AI确实可能赋予基层单元更大的自主权,使其能够基于本地知识做出更精准的决策;另一方面,边缘AI的设计、训练和规则制定仍然掌握在少数技术寡头手中,这可能导致一种新的隐性控制形式——决策虽然发生在边缘,但决策的框架和边界仍然由中心定义。
问责体系的重建
任何决策体系的核心问题都是"谁来负责"。传统层级制的优势在于责任链条清晰,每个决策节点都可以被追溯和问责。边缘AI决策面临的核心挑战是:当一个AI系统在地方做出导致负面后果的决策时,责任应该如何分配?
可能的路径包括:开发者承担技术责任,使用者承担应用责任,监管机构承担监督责任。但这种责任分担机制在实践中可能面临重重困难,特别是在跨境、跨部门的复杂场景中。
信任结构的重塑
人类社会运作的基础之一是信任——公民对政府、机构对个人、个人对系统的信任。AI辅助决策可能从根本上改变这种信任结构。一方面,AI决策可能因为其客观性和一致性而获得更高信任;另一方面,算法黑箱和缺乏解释性的决策过程可能引发新的不信任。
更重要的是,当人类开始习惯于AI辅助甚至主导的决策时,是否会逐渐丧失独立判断的意愿和能力?这是一个关乎人类主体性的深层问题。
4.5.2.2 幸福感的辩证¶
回到你最核心的关切:我们会因此更幸福还是不幸?这个问题没有简单的答案,因为它取决于我们如何定义幸福以及谁来决定这个定义。
-
可能的福祉提升
-
效率增益带来的生活质量改善:更快的应急响应意味着更少的生命财产损失;更精准的资源配置意味着更少的浪费和延误;更及时的公共服务意味着更少的等待和不便。这些都是可以客观衡量的福祉提升。
-
赋权于个体和社区:当决策能够基于更充分的本地信息和更及时的反馈时,结果可能更符合社区的实际需求。这与"参与式民主"的理念有某种共鸣——但现在是通过AI来实现这种参与。
-
减轻人类的认知负担:许多日常决策是消耗精力的琐事,AI辅助决策可以让人类专注于更有创造性、更有意义的事务。
-
-
潜在的风险和代价
-
异化和失控感:当重要决策越来越多地由非人类的AI系统做出时,人们可能感到自己被排斥在影响自身生活的关键过程之外。这种异化感可能是幸福感的重大威胁。
-
同质化与多样性的丧失:边缘AI虽然部署在各地,但如果它们都基于相似的基础模型训练,决策逻辑可能趋向同质化。人类社会的魅力之一在于其多样性——不同文化、传统、价值观孕育出的丰富实践。如果AI将这种多样性"优化"掉,可能导致一个更高效但也更单调的世界。
-
新的脆弱性和不平等:依赖于复杂AI系统的社会可能面临新的系统性风险。AI系统的漏洞或被恶意利用可能导致大规模故障。同时,能够开发和部署先进边缘AI的主体将获得巨大优势,可能加剧已有的不平等。
-
意义感的危机:许多人类活动的重要意义来自于决策过程中的挣扎、选择和承担后果。完全的AI决策可能剥夺这种"存在的重量",让人变成被服务的客体而非行动的主体。
-
4.5.2.3 历史的启示与未来的选择¶
回顾人类历史上几次重大的"权力下放"尝试,我们会发现:制度变革本身是中性的,其结果取决于实施的具体形式和配套的社会条件。
英国普通法传统下的地方自治带来了高度的社区凝聚力和创新活力;苏联模式的"去中心化"尝试最终导致的是经济低效和更大的权力集中。技术赋能只是变革的可能条件,而非充分条件。
对于AI边缘决策这一前景,有几个关键的选择点将决定其走向:
-
谁设计边缘AI的目标函数? 如果边缘AI的优化目标由远离基层的精英群体设定,那么"边缘决策"可能只是另一种形式的控制。真正有意义的下放需要基层参与目标定义。
-
如何保持人类的主体性? AI应该扮演辅助和建议的角色,而非最终的裁决者。保留人类否决权和最终决策权可能是避免异化的关键。
-
如何建立新型问责机制? 需要开发新的法律、伦理和技术框架来确保边缘AI决策的问责性。这可能包括可解释AI、算法审计、集体追责等机制。
-
如何平衡效率与多样性? 在追求决策优化的同时,需要有意识地保护不同声音和非常规方案的空间。
我的判断是:如果边缘AI决策能够以上述原则为导向实施,它确实有潜力让人类社会更高效、更公平、更人性化。但这绝非技术的自然演化结果,而是需要广泛的社会讨论、谨慎的制度设计和持续的批判性反思。
你提到的"边缘计算"隐喻揭示了一个深刻的真理:架构的改变可以带来能力的跃升。但在社会领域,架构不仅是技术问题,更是权力、利益和价值观的博弈场所。最终塑造这个未来的,不是算法,而是我们关于"好的社会应该是什么样子"的集体想象。